
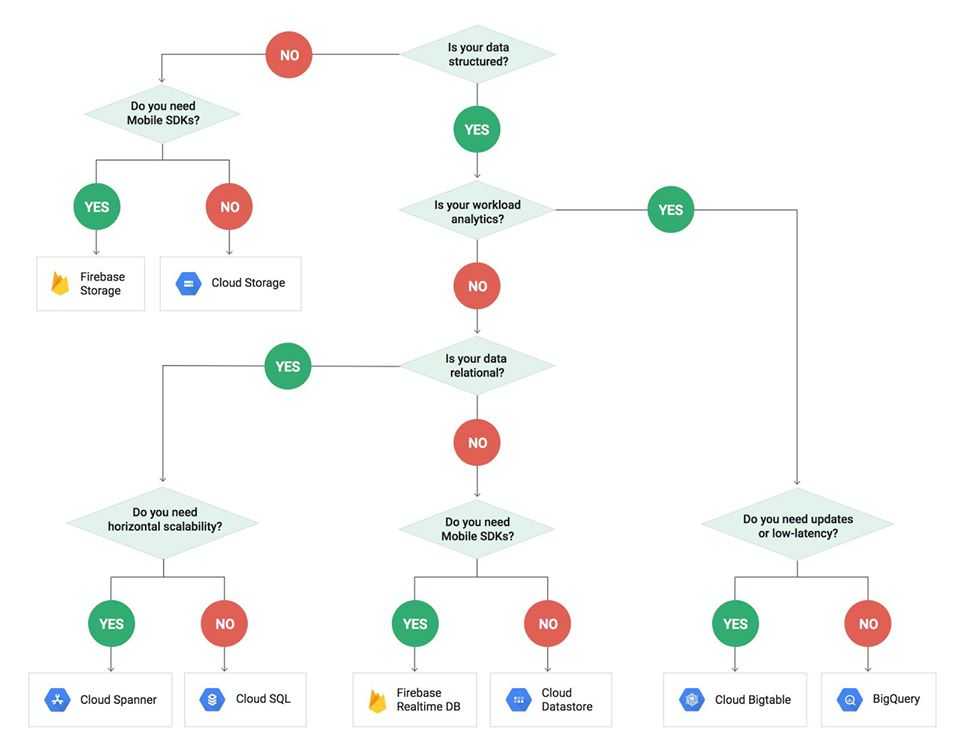
Большой стол
Некоторые функции
- быстрая и чрезвычайно масштабная СУБД
- разреженная, распределенная многомерная отсортированная карта, разделяющая характеристики как ориентированных на строки, так и ориентированных на столбцы баз данных.
- предназначен для масштабирования в петабайтный диапазон
- он работает на сотнях или тысячах машин
- легко добавить больше компьютеров в систему и автоматически начать использовать эти ресурсы без какой-либо реконфигурации
- каждая таблица имеет несколько измерений (одно из которых является полем времени, позволяющим управлять версиями)
- Таблицы оптимизированы для GFS (файловой системы Google), поскольку они разбиты на несколько планшетов — сегменты таблицы разделены по выбранной строке так, что размер планшета составит ~ 200 мегабайт.
Архитектура
BigTable не является реляционной базой данных. Он не поддерживает объединения и не поддерживает расширенные SQL-подобные запросы. Каждая таблица представляет собой многомерную разреженную карту. Таблицы состоят из строк и столбцов, и каждая ячейка имеет метку времени. Может быть несколько версий ячейки с разными отметками времени. Отметка времени позволяет выполнять такие операции, как «выбрать ‘n’ версии этой веб-страницы» или «удалить ячейки, которые старше определенной даты / времени».
Таблицы хранятся как неизменяемые SSTables и хвост журналов (один журнал на машину). Когда машине не хватает системной памяти, она сжимает некоторые планшеты, используя собственные методы сжатия Google (BMDiff и Zippy). Незначительные уплотнения включают только несколько планшетов, в то время как крупные уплотнения затрагивают всю систему таблиц и восстанавливают пространство на жестком диске.
Расположение планшетов Bigtable хранится в клетках. Поиск любого конкретного планшета обрабатывается трехуровневой системой. Клиенты получают точку в таблице META0, из которых есть только одна. Таблица META0 отслеживает многие планшеты META1, в которых указаны местоположения просматриваемых планшетов. И META0, и META1 интенсивно используют предварительную выборку и кэширование, чтобы минимизировать узкие места в системе.
Реализация
BigTable построен на файловой системе Google (GFS), которая используется в качестве резервного хранилища для файлов журналов и данных. GFS обеспечивает надежное хранилище для SSTables, проприетарного формата файлов Google, используемого для сохранения табличных данных.
Еще одна служба, которую BigTable интенсивно использует, — это Chubby , высокодоступная и надежная служба распределенной блокировки. Chubby позволяет клиентам взять блокировку, возможно, связав ее с некоторыми метаданными, которые он может обновить, отправив сообщения о том, что они активны, обратно в Chubby. Блокировки хранятся в иерархической структуре именования, подобной файловой системе.
Существует три основных типа сервера , представляющих интерес для системы Bigtable:
- Главные серверы: назначайте планшеты планшетным серверам, отслеживайте расположение планшетов и перераспределяйте задачи по мере необходимости.
- Планшетные серверы: обрабатывают запросы на чтение / запись для планшетов и разделенных планшетов, когда они превышают предельные размеры (обычно 100–200 МБ). Если происходит сбой планшетного сервера, то на 100 планшетных серверах каждый забирает 1 новый планшет, и система восстанавливается.
- Блокировка серверов: экземпляры службы распределенной блокировки Chubby. Множество действий в BigTable требует приобретения замков, включая открытие планшетов для записи, обеспечение того, чтобы одновременно было не более одного активного мастера, и проверку контроля доступа.
Пример из исследования Google:
![]()
API
Типичными операциями для BigTable являются создание и удаление таблиц и семейств столбцов, запись данных и удаление столбцов из строки. BigTable предоставляет эти функции разработчикам приложений в API. Транзакции поддерживаются на уровне строк, но не для нескольких ключей строк.
Вот ссылка на PDF-файл исследовательской статьи.
А здесь вы можете найти видео с Джеффом Дином из Google в лекции в Вашингтонском университете, где обсуждалась система хранения контента Bigtable, используемая в серверной части Google.
592
12 revs, 4 users 97%
18 Мар 2015 в 07:29
Разбираемся в задачах
Итак мы компания среднего бизнеса. Торгуем оптом строительными материалами. Что у нас есть:
-
ERP система в компании (например: 1С или Axapta)
-
CRM система (Amo CRM или Bitrix 24)
-
Облачная система для учета товаров которая используется в одном из филиалов (Мой склад)
-
Интернет магазин написанный на PHP с подключенным Google Analytics
Что нам нужно: строить консолидированную отчетность на основании данных их всех этих источников.
Как решаем сейчас: делаем отчеты в каждой из этих систем, все выгружаем в Excel, в нем сводим, высылаем отчеты в Excel пользователям по почте. Есть отчеты которые нужны каждый месяц: ежемесячно тратим время на их сведение и подготовку. Есть отчеты, которые нужны каждую неделю: теряем время еженедельно. Есть отчеты, которые нужны каждый день, но их не делаем: нет времени, отправляем их раз в неделю.
Пример из жизни. Работа с GDPR
Нам пришлось столкнуться с задачей анонимизации данных по регламенту GDPR для Google Analytics (GA) в BigQuery. Задача заключалась в том, что каждый день в BigQuery импортировались данные из Google Analytics (GA). Поскольку в GA хранились персональные данные пользователей, для удалённых пользователей необходимо было очищать персональную информацию по регламенту GDPR. Данные, которые необходимо было анонимизировать, находились в поле с типом array. Аккаунт BigQuery, который нам предоставили, работал с ценовой моделью On-demand, в которой стоимость рассчитывалась из обработанных данных каждого запроса. Данные хранились в шард-таблицах. Google не рекомендует использовать шардированные таблицы и предлагает взамен партиционирование + кластеризацию, но, к сожалению, в Google Analytics (GA) это стандартная структура хранения данных. При экспорте данных из Google Analytics в BQ создаётся шард-таблица ga_sessions_, сегментированная по датам. В таблице находится порядка 16 полей, для нашей задачи необходимы были поля:
-
fullVisitorId (string) — уникальный идентификатор посетителя GA (также известный как идентификатор клиента)
-
customDimensions (array) — поле с типом array, содержит пользовательские данные, которые устанавливаются для каждого сеанса пользователя.
В поле customDimensions хранятся значения (идентификаторы), которые нам необходимо анонимизировать. Значения хранятся под определёнными индексами в массиве customDimensions.





Решение задачи
Мы создали в BQ таблицу opted_out_visitors для хранения пользователей, информацию о которых необходимо анонимизировать.
Схема таблицы:
В данной таблице мы храним копию данных из ga_sessions_, которые подпадают под регламент GDPR.
При получении запроса на удаление пользователя в нашей системе мы находили в таблицах GA данные пользователя для анонимизации и добавляли значения в таблицу opted_out_visitors:
где cd.index=11 — индекс массива customDimensions, в котором хранятся идентификаторы пользователя, а cd.value=»1111111″ — идентификатор пользователя, данные которого необходимо почистить в таблицах GA. Собственно, в данной таблице мы имеем идентификатор пользователя в сеансе GA (fullVisitorId), данные пользователя (customDimensions) для анонимизации и дату, когда пользователь оставил за собой следы. После добавления данных в таблицу opted_out_visitors чистим значение, которое необходимо заменить.
Осталось почистить значения в оригинальных таблицах GA. Для этого мы раз в 7 дней запускаем скрипт, который обновляет данные в ga_sessions для каждой даты в opted_out_visitors:
После этого очищаем таблицу opted_out_visitors.
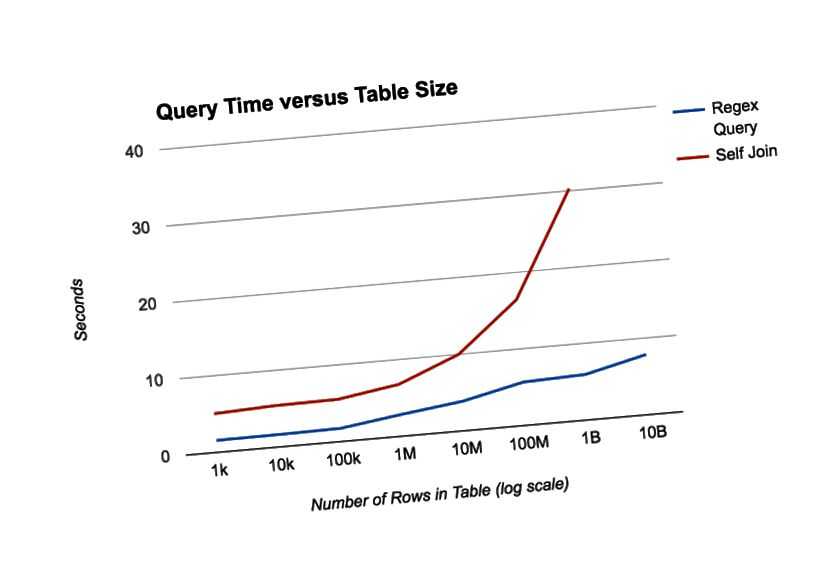
Многие читатели могут подумать, зачем так запариваться, создавать отдельную таблицу opted_out_visitors, хранить там идентификаторы из ga_sessions с анонимизированными данными, а потом всё это мержить раз в N дней. Дело в том, что каждая таблица ga_sessions занимает около 10 ГБ, и с каждым днём количество таблиц увеличивалось. Если бы мы выполняли анонимизацию данных каждый раз при поступлении запроса на удаление, мы получили бы огромные затраты в BigQuery. Но и с данным подходом нам не удалось добиться минимальных затрат. После анализа всех запросов мы выявили, что проблемным местом является запрос поиска анонимных данных и добавления в таблицу opted_out_visitors.
В данном запросе мы обращаемся к таблице ga_sessions_ за весь период, откуда получаем данные из столбца customDimensions (напомним, что этот столбец имеет тип array, который может хранить в себе любой объём данных). В итоге один запрос весил около 40 ГБ, так как BigQuery сканировал все таблицы ga_sessions_ и искал информацию в столбце customDimensions. Таких запросов в день было 50–80. Таким образом, меньше чем за день мы тратили весь бесплатный месячный трафик (1 ТБ).
Как изменить условия подписки Google One
Вы можете выбрать тарифный план с увеличенным или уменьшенным объемом хранилища, а также изменить периодичность оплаты – ежемесячно или ежегодно.
Как изменить тарифный план Google One
Чтобы перейти на другой тарифный план Google One:
Откройте страницу one.google.com в браузере на компьютере.
В левой части страницы нажмите на значок «Настройки» Изменить тарифный план.
Выберите новый план.
Если вы хотите увеличить пространство, выберите нужный вариант в разделе «Планы с увеличенным объемом хранилища».
Чтобы уменьшить пространство и платить меньше, обратите внимание на раздел «Планы с уменьшенным объемом хранилища».Примечание. Если этого раздела нет, это значит, что у вас самый экономичный план.
Проверьте и подтвердите новую стоимость и условия, а затем нажмите Продолжить.
Выберите способ оплаты и нажмите Подписаться.
Как выбрать тарифный план
Если впоследствии вы захотите выбрать другой тарифный план, вы также сможете перейти с ежемесячной на ежегодную оплату и наоборот.
- Откройте страницу one.google.com в браузере на компьютере.
- В левой части страницы нажмите на значок «Настройки» Изменить тарифный план.
- Выберите подписку с ежемесячной или ежегодной оплатой.
- Проверьте и подтвердите новую стоимость и условия, а затем нажмите Продолжить.
- Выберите способ оплаты и нажмите Подписаться.
Локальный запуск
Для локального запуска приложений можно воспользоваться cartridge-cli, но сначала нужно добавить написанные нами роли в replicasets.yml:
С параметрами запускаемых инстансов можно ознакомиться в instances.yml.
Запускаем кластер локально:
Теперь мы можем зайти в webui и загрузить конфигурацию ролей, а также настроить фейловер. Чтобы настроить stateful failover, необходимо:
- нажать на кнопку Failover
- выбрать stateful
- прописать адрес и пароль:
- localhost:4401
- passwd
Давайте посмотрим на его работу. Сейчас в репликасете лидером является .
Остановим его:
Лидер переключится на :
Восстановим :
поднялся, но благодаря stateful-фейловеру лидером остается :
Загрузим конфигурацию для роли , для этого необходимо перейти на вкладку Code и создать файл metrics.yml следующего содержания:
После того, как мы нажмем на кнопку Apply, метрики будут доступны на каждом узле приложения по эндпоинту и появится health-check по адресу .
На этом базовая настройка небольшого приложения завершена: кластер готов к работе и теперь мы можем написать приложение, которое будет общаться с кластером с помощью HTTP API или через коннектор, а также можем расширять функциональность кластера.
Добиться консенсуса
Дирижирование согласованной работой множества таблет-серверов в архитектуре Bigtable берет на себя Bigtable Master – процесс, выполняющийся на одном из серверов . Он отвечает за размещение таблетов на таблет-серверах, обнаружение, добавление или удаление таблет-серверов в уже существующей их инфраструктуре и балансировку их загрузки. Кроме того, Bigtable Master поддерживает схему изменений общей таблицы Bigtable, например, редактирование состава семейства столбцов или форматов timestamps.





Управление синхронизацией операций чтения/записи одних и тех же данных множеством клиентов не входит в задачу мастера Bigtable. Как же в таком случае быть с блокировкой доступа к строкам таблетов в том случае, если один из клиентов решить изменить в ее семействах столбцов данные или же записать новые?
В системах обработки информации с этой проблемой, обычно справляются сами обработчики. Правда, не без помощи таких синхронизирующих объектов, как блокирующие переменные, семафоры, мьютексы и иже с ними.
Bigtable — это чересчур большая и распределенная система для таких синхонизирующих объектов, поэтому вместо них применяется распределённый сервис блокировок (distributed lock service), который в именуют Chubby. Его роль в Bigtable можно сравнить с ролью транзакций в обычных СУБД.
![]()
В кластере Bigtable два дирижера: Bigtable Master и сервис блокировок Chubby. Первй отвечает за масштабируемость и отказоустойчивость, а второй за синхронизацию и учет данных.
Для каждого таблет-сервера Chubby создает специальный chubby-файл. Благодаря этому файлу Bigtable Master всегда в курсе того, какие из серверов работоспособны. Еще один chubby-файл содержит ссылку на расположение таблета всех таблетов — корневого таблета (Root-tablet) с данными о расположении всех остальных таблетов. Этот файл сообщает мастеру, какой из серверов какими таблетами управляет.
Безусловно, использование сервиса Chubby в Bigtable в какой-то мере решает задачу поддержания непротиворечивости данных в распределенной среде с множеством реплик. Но непротиворечивость бывает разной. Bigtable стала первой попыткой достичь баланса между производительностью системы, ее масштабируемостью и непротиворечивостью хранящихся в ней данных. Результатом стала поддержка так называемой слабой непротиворечивости, которая, в принципе, удовлетворяла требованиям большинства работающих с Bigtable сервисов.
![]()
Процесс взаимодействия всех компонентов Bigtable и используемые для этого информационные структуры.
Увы, слабая непротиворечивость подходит не всегда. Именно поэтому инженеры не покладая рук трудились над эволюционным развитием Bigtable. В результате их работы в 2011 году появилось распределенное хранилище Spanner – практически бескомпромиссное решение, вплотную приблизившееся к возможностям распределенных реляционных баз данных. Но рассказ о нем – совершенно отдельная история.
Почему стоит выбрать именно Google BigQuery
Скорость — это основное преимущество BigQuery, но не единственное. BigQuery — облачный сервис. При его использовании не понадобится арендовать сервер и оплачивать поддержку.
Стоимость BigQuery значительно ниже стоимости аренды самого примитивного сервера: даже если вы очень постараетесь и будете ежедневно записывать в эту базу данных миллионы строк, все равно вряд ли сможете потратить более $5.
Следующее преимущество — простота использования. В любой другой системе управления базами данных (СУБД) помимо знания SQL придется долго разбираться с тонкостями администрирования и настройками базы.
И если сам по себе SQL-диалект во всех базах данных очень похожий, то административная часть, как правило, везде устроена по-разному.
У BigQuery всю административную часть на себя взял Google. В этом сервисе нет никаких настроек, индексов, движков таблиц, тайм-аутов или внешних ключей. Реализована поддержка только одной кодировки UTF-8.
Для работы с BigQuery достаточно знать, как загрузить данные в BigQuery, и иметь базовые знания в SQL.
Несмотря на простоту, в BigQuery реализована поддержка практически всех функций СУБД:
-
оконные функции;
- хранение данных в виде структур (нереляционные возможности);
- представления и табличные выражения (common table expression).
Правда, на момент публикации статьи сервис не поддерживает:
- рекурсивные запросы;
- создание хранимых процедур и функций;
- транзакции.
Пишем бизнес-логику в Cartridge
В основе каждого кластерного приложения лежат роли — Lua-модули, в которых описывается бизнес-логика приложения. Например, это могут быть модули, которые занимаются хранением данных, предоставляют HTTP API или кэширует данные из Oracle. Роль назначается на набор инстансов, объединенных репликацией (репликасет) и включается на каждом из них. У разных репликасетов может быть разный набор ролей.
В cartridge есть кластерная конфигурация, которая хранится на каждом из узлов кластера. Там описывается топология, а также туда можно добавить конфигурацию, которой будет пользоваться ваша роль. Такую конфигурацию можно изменять в рантайме и влиять на поведение роли.
Каждая роль имеет структуру следующего вида:
Жизненный цикл роли
- Инстанс запускается.
- Роль с именем ждет запуска всех зависимых ролей, указанных в .
- Вызывается функция , которая проверяет валидность конфига роли.
- Вызывается функция инициализации роли , в которой производятся действия, которые должны запускаться один раз на старте роли.
- Вызывается , которая применяет конфиг (если таковой имеется). и вызываются также при каждом изменении конфигурации роли.
- Роль попадает в registry, откуда будет доступна для других ролей на этом же узле с помощью.
- Объявленные в роли функции будут доступны для вызова с других узлов с помощью.
- Перед выключением или перезапуском роли запускется функция , которая завершает работу роли, например, удаляют созданные ролью файберы.
Создание репозитория с файлами CDH
Для эксплуатации разработанного функционала нам также требовался Spark 2.2, не входящий в парсэль CDH (там доступна первая версия данного сервиса). Для его установки требуется загрузить отдельный парсэль с данным сервисом и соответствующий manifest.json, также доступные в архиве Cloudera.
После загрузки парсэлей и manifest.json требуется перенести их в соответствующие папки нашего репозитория. Создаем отдельные папки для файлов CDH и Spark:
Переносим в созданные папки парсэли и файлы manifest.json. Чтобы сделать их доступными для установки по сети выдаем папке с парсэлями соответствующие доступы:
Можно приступать к установке CDH, о чем я расскажу в следующем посте.
Ограничения
Bigtable обладает рядом ограничений:
- Не поддерживаются транзакции на уровне нескольких строк (только на уровне одной строки);
- Определение способа хранения данных – RAM или диск – ответственность клиента. Bigtable не пытается определить наилучший способ хранения динамически;
-
На момент публикации research paper , описывающего принципы построения Bigtable, система
не обладала возможностью репликации через географически удаленные датацентры; - На момент публикации , хранилище не обладало возможность построения вторичных индексов;
- Зависимость от сервиса распределенных блокировок Chubby – если Chubby не отвечает (такое бывает менее 0,01% времени, то и Bigtable-кластер не доступен.
Особенности SQL для Google BigQuery
BigQuery умеет переключаться между стандартным SQL и диалектами.
DML-операции INSERT, UPDATE и DELETE на данный момент поддерживаются только при использовании стандартного SQL.
Еще одно отличие между этими диалектами — способ вертикального объединения таблиц. В стандартном SQL для этого служит оператор UNION и ключевое слов ALL или DISTINCT:
В собственном SQL-диалекте функционал для вертикального объединения таблиц значительно шире. Существует специальный набор функций подстановки таблиц ().






Этот способ объединения таблиц я уже подробно описывал ранее.
Для простого объединения достаточно просто перечислить названия нужных таблиц или подзапросы через запятую. Объединение запросов из примера выше на внутреннем диалекте SQL в BigQuery будет выглядеть так:
Переключатель между SQL-диалектами в BigQuery находится в интерфейсе в блоке опций: нажмите кнопку Show options под редактором запросов.
![]()
С помощью галочки «SQL Dialect» переключитесь на нужный диалект.
![]()
Цели проекта
Во-первых, оптимизировать работу департамента управления рисками. До начала работ расчетом факторов кредитного риска (ФКР) занимался целый отдел, и все расчеты производились вручную. Перерасчет занимал каждый раз около месяца и данные, на основе которых он базировался, успевали устареть. Поэтому в задачи решения входила ежедневная загрузка дельты данных в хранилище, перерасчет ФКР и построение витрин данных в BI-инструменте (для данной задачи оказалось достаточно функционала SpagoBI) для их визуализации.
Во-вторых, обеспечить высокопроизводительные инструменты Data Mining для сотрудников банка, занимающихся Data Science. Данные инструменты, такие как Jupyter и Apache Zeppelin, могут быть установлены локально и с их помощью также можно исследовать данные и производить построение моделей. Но их интеграция с кластером Cloudera позволяет использовать для расчетов аппаратные ресурсы наиболее производительных узлов системы, что ускоряет выполнение задач анализа данных в десятки и даже сотни раз.
В качестве целевого аппаратного решения была выбрана стойка Oracle Big Data Appliance, поэтому за основу был взят дистрибутив Apache Hadoop от компании Cloudera. Стойка ехала довольно долго, и для ускорения процесса под данный проект были выделены сервера в приватном облаке заказчика. Решение разумное, но был и ряд проблем, о которых расскажу ниже по тексту.
В рамках проекта были запланированы следующие задачи:
- Развернуть Cloudera CDH (Cloudera’s Distribution including Apache Hadoop) и дополнительные сервисы, необходимые для работы.
- Произвести настройку установленного ПО.
- Настроить непрерывную интеграцию для ускорения процесса разработки (будет освещена в отдельной статье).
- Установить BI-средства для построения отчетности и инструментов Data Discovery для обеспечения работы датасайентистов (будет освещена в отдельном посте).
- Разработать приложения для загрузки необходимых данных из конечных систем, а также их регулярной актуализации.
- Разработать формы построения отчетности для визуализации данных в BI-средстве.
Компания Neoflex не первый год занимается разработкой и внедрением систем на базе Apache Hadoop и даже имеет свой продукт для визуальной разработки ETL-процессов — Neoflex Datagram. Я давно хотел принять участие в одном из проектов этого класса и с радостью занялся администрированием данной системы. Опыт оказался весьма ценным и мотивирующим к дальнейшему изучению темы, поэтому спешу поделиться им с вами. Надеюсь, что будет интересно.
Подготовьте проект для BigQuery Export
- Убедитесь, что в проекте настроена оплата.
Если оплата не настроена, откройте меню навигации в левом верхнем углу и нажмите Оплата. - При необходимости создайте платежный аккаунт.
Он требуется для осуществления оплаты. Один платежный аккаунт может использоваться несколькими проектами. Чтобы создать платежный аккаунт, следуйте инструкциям в API Console. - Примите бесплатную пробную версию, если она доступна.
При этом вам все равно нужно будет указать платежную информацию, чтобы сервис продолжал получать экспортированные данные после того, как срок действия пробной версии закончится. - Убедитесь, что оплата возможна.
Откройте проект на странице https://console.cloud.google.com/bigquery и попробуйте создать набор данных. Нажмите на синюю стрелку рядом с названием проекта, затем выберите Создать набор данных. Если у вас получится создать набор данных, значит, оплата настроена правильно. В случае ошибки еще раз проверьте, настроена ли оплата. - Добавьте в проект сервисный аккаунт.
Добавьте аккаунт analytics-processing-dev@system.gserviceaccount.com в качестве участника проекта и предоставьте ему разрешение Редактор на уровне проекта (не путать с Редактором данных BigQuery). Это необходимо для экспорта данных из Google Аналитики в BigQuery.
Проблемы с хранилищем
Участники семейной группы используют слишком много места
По умолчанию участникам семейной группы доступен весь объем хранилища. Если один из участников использует слишком много места, попросите его .
Если вы не хотите использовать хранилище совместно с другими участниками семейной группы, доступ к подписке Google One можно закрыть.
После смены тарифного плана объем хранилища не изменилсяДополнительное пространство становится доступно в течение 24 часов после оплаты. Проверьте объем хранилища через сутки.
Объем доступного пространства в хранилище не увеличился так, как ожидалось
Примечание. Если вы смените тарифный план, на вступление изменений в силу может потребоваться до 24 часов.
Подписка Google One заменяет ваш текущий план. Объем доступного пространства определяется настройками тарифного плана Google One, а не добавляется к имеющемуся у вас объему.
Если ранее вы получили дополнительное пространство по условиям промоакции, оно у вас останется.
Подробнее о том, как меняется объем хранилища при оформлении подписки Google One…
Объем доступного пространства не увеличился после удаления некоторых файлов
Не все файлы занимают пространство в хранилище. Например, письма, перемещенные в корзину Gmail, не занимают пространство, а файлы в корзине Диска – занимают.
Подробнее о том, …
После покупки дополнительного места письма не приходят и не отправляются
Если вы сменили тарифный план, на вступление изменений в силу может потребоваться до 24 часов. В течение этого периода могут наблюдаться проблемы с получением и отправкой писем в Gmail. Попробуйте выполнить следующие действия:
- Выйдите из своего аккаунта Google, а затем войдите в него снова.
- Отправьте пробное письмо на свой адрес.
- Если проблема сохраняется:
- Откройте новое окно в режиме инкогнито и войдите в свой аккаунт Gmail. Попробуйте отправить письмо.
- Войдите в аккаунт в другом браузере, например Internet Explorer или Firefox. Попробуйте отправить письмо.
Если проблема сохраняется, повторите попытку через 24 часа.
Что произойдет, если у вас закончилось пространство в хранилище
Ранее загруженные вами файлы сохранятся, но вы не сможете добавлять новые. Пример:
Gmail
Вы не сможете получать или отправлять письма. Письма, адресованные вам, будут возвращены отправителю.








Важно! С 1 июня 2021 года вступило в силу новое правило: если в течение двух и более лет вы не используете аккаунт или в нем превышена квота на хранение, все ваши письма могут быть удалены
Google Диск
Вы не сможете синхронизировать и загружать новые файлы, а также создавать файлы с помощью Google Документов, Таблиц, Презентаций, Рисунков, Форм и Jamboard. Пока не освободите место в хранилище, ни вы, ни пользователи, которым предоставлен доступ к файлам, не сможете копировать или редактировать их. Синхронизация между папкой Google Диска на компьютере и разделом «Мой диск» будет остановлена.
Важно! С 1 июня 2021 года вступило в силу новое правило: если в течение двух и более лет вы не используете аккаунт или в нем превышена квота на хранение, все ваши письма могут быть удалены
Google Фото
Вы не сможете загружать фотографии и видео, пока не освободите место в хранилище или не купите дополнительное пространство.
Важно! С 1 июня 2021 года вступило в силу новое правило: если в течение двух и более лет вы не используете аккаунт или в нем превышена квота на хранение, все ваши письма могут быть удалены. Подробнее о том, как освободить место на Google Диске…
Подробнее о том, как освободить место на Google Диске…
Если при оформлении подписки не использовался аккаунт Apple
Если вы оформили подписку на сайте Google One или на другом устройстве, но не использовали свой аккаунт Apple:
- вы можете скачать приложение Google One на свое устройство iOS;
- внести изменения в тарифный план Google One на своем устройстве нельзя.
Чтобы вносить изменения в настройки аккаунта Google One и управлять подпиской в приложении, используйте при ее оформлении свой аккаунт Apple.
На компьютере
- Откройте сайт Google One в браузере.
- Отмените действующую подписку Google One.
Шаг 2. Оформите подписку Google One через приложение
На устройстве iOS
- Скачайте приложение Google One в App Store.
- Откройте приложение Google One .
- В верхнем левом углу экрана нажмите на значок меню Тарифный план.
- Выберите нужный план.
- Подтвердите подписку в своем аккаунте Apple.
Ценообразование
BigQuery предлагает несколько вариантов ценообразования в соответствии с техническими потребностями. Все расходы, связанные с выполнением заданий BigQuery в проекте, оплачиваются через привязанный платёжный аккаунт. Затраты формируются из двух составляющих:
-
хранение данных
-
обработка данных во время выполнения запросов.
Стоимость хранения зависит от объёма данных, хранящихся в BigQuery.
-
Active. Ежемесячная плата за данные, хранящиеся в таблицах или разделах, которые были изменены за последние 90 дней. Плата за активное хранение данных составляет 0,020 $ за 1 ГБ, первые 10 ГБ — бесплатно каждый месяц. Стоимость хранилища рассчитывается пропорционально за МБ в секунду.
-
Long-term. Плата за данные, хранящиеся в таблицах или разделах, которые не были изменены в течение последних 90 дней. Если таблица не редактируется в течение 90 дней подряд, стоимость хранения этой таблицы автоматически снижается примерно на 50%.
Что касается затрат на запрос, вы можете выбрать одну из двух моделей ценообразования:
-
On-demand. Цена зависит от объёма данных, обрабатываемых каждым запросом. Стоимость каждого терабайта обработанных данных составляет 5,00 $. Первый обработанный 1 ТБ в месяц бесплатно, минимум 10 МБ обрабатываемых данных на таблицу, на которую ссылается запрос, и минимум 10 МБ обрабатываемых данных на запрос. Важный момент: оплата происходит за обработанные данные, а не за данные, полученные после выполнения запроса.
-
Flat-rate. Фиксированная цена. В данной модели выделяется фиксированная мощность на выполнение запросов. Запросы используют эту мощность, и вам не выставляется счёт за обработанные байты. Мощность измеряется в слотах. Минимальное количество слотов — 100. Стоимость за 100 слотов — 2000 $ в месяц.
-





Стоит заметить, что хранение данных часто обходится значительно дешевле, чем обработка данных в запросах.Бесплатные операции:
-
Загрузка данных. Не нужно платить за загрузку данных из облачного хранилища или из локальных файлов в BigQuery.
-
Копирование данных. Не нужно платить за копирование данных из одной таблицы BigQuery в другую.
-
Экспорт данных. Не нужно платить за экспорт данных из других сервисов, например из Google Analytics (GA).
-
Удаление наборов данных (датасетов), таблиц, представлений, партиций и функций.
-
Операции с метаданными таблиц. Не нужно платить за редактирование метаданных.
-
Чтение данных из метатаблиц __PARTITIONS_SUMMARY__ и __TABLES_SUMMARY__.
-
Все операции UDF. Не нужно платить за операции создания, замены или вызова функций.
Будущее и итоги
Bigtable, без сомнения, была самой большим по объему хранимых данных NoSQL базой в мире. Более того, концепции, лежащие в основе Bigtable и
описанные в , легли в основу многих популярных сегодня NoSQL-решений, в т.ч. HBase – NoSQL БД, входящая в .
Тем не менее, хорошо знакомые сообществу достоинства и ограничения NoSQL-решений также свойственны и Bigtable. В какой-то момент времени
у некоторых из сервисов Google появилось критичное требование – поддержка принципа ACID для распределенных транзакций.
Ни NoSQL-решения, в общем случае, ни Bigtable, в частности, не могли реализовать поддержку данного требования.
Так инженерами Google была начата работа над распределенным хранилищем нового поколения, которое можно отнести к классу NewSQL.
На сегодняшний день это хранилище известно как Spanner.
Архитектура этого хранилища будет описана в одной из следующих статей из цикла.