
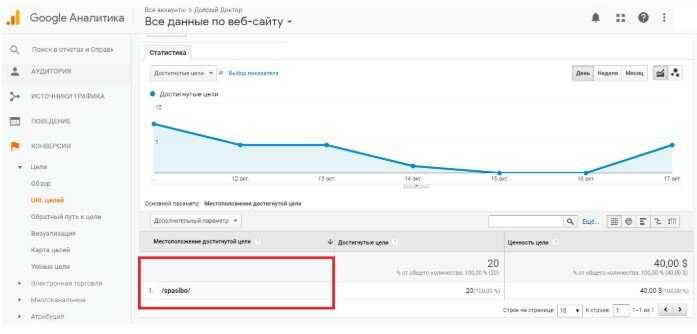
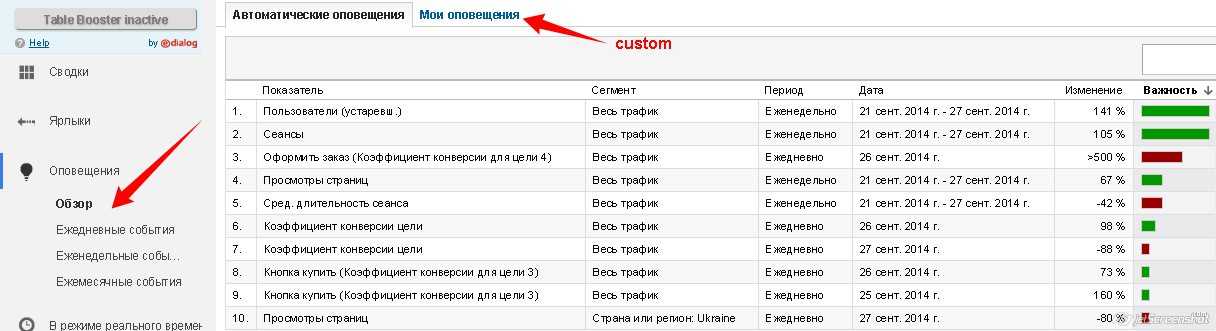
Альтернативные инструменты
Есть ли альтернатива Google Trends? Бесплатного инструмента, полностью аналогичного по функционалу, на данный момент нет. Но есть отдельные возможности других сервисов, которые можно использовать для перечисленных сценариев.
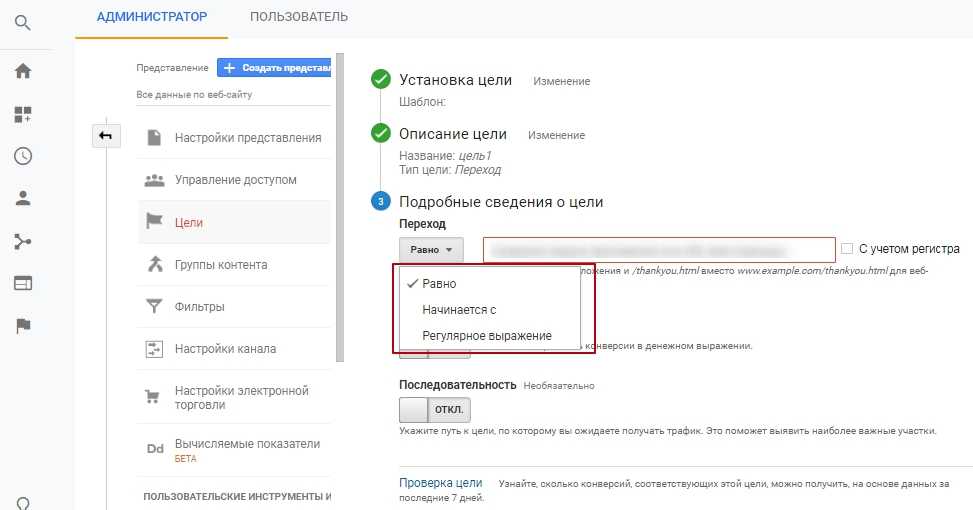
Подбор слов от Яндекса
Некоторые функции Google Trends могут выполнять вкладки в сервисе Подбор слов от Яндекса. При сборе семантики чаще всего используют раздел, который доступен по умолчанию — «По словам». Но два других — «По регионам» и «История запросов» — помогут получить дополнительные важные сведения.
Популярность того или иного запроса в разрезе регионов покажет вкладка «По регионам». Статистику можно фильтровать по устройствам и выбирать для показа регионы или города:
Помимо списка доступно представление в виде тепловой карты:
Сезонные всплески интереса можно отследить во вкладке «История запросов»:
Представлена статистика за два года, доступна группировка по неделям и месяцам, фильтрация по пользовательским устройствам.
Инструмент от Яндекса содержит часть функционала, аналогичного Google Trends — определение популярности запроса в регионах и сезонности спроса. Также не забудьте, что в Вордстате содержатся данные другой поисковой системы, которая ориентирована на рунет. Если хотите узнать тенденции за пределами России, лучше использовать инструмент от Google.
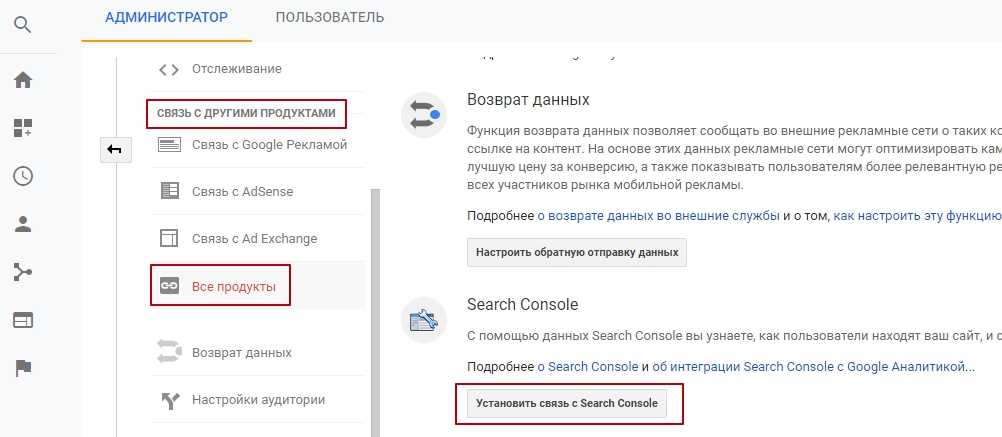
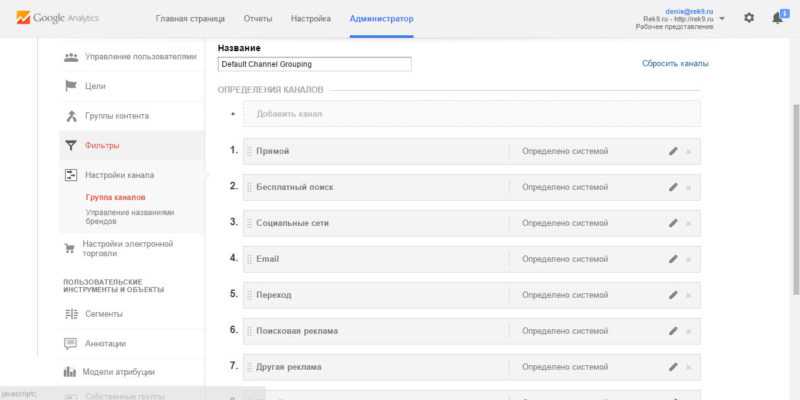
Функционал медиапланирования в системе Click.ru
Функционал Планировщика ключевых слов от Google, Подбора слов от Яндекса и частично Google Trends, полезный для создания кампаний в контекстной рекламе, совмещает бесплатный инструмент подбора слов и медиапланирования в Click.ru.
Инструмент подберет ключевые слова из разных источников, расширит семантику средне- и низкочастотными запросами и спрогнозирует бюджет в Яндекс.Директе и Google Ads. Доступна автоматическая кросс-минусовка и рекомендации по добавлению минус-слов.
Что изменилось
С февраля 2021 года Google Ads объединил фразовый тип соответствия и модификатор широкого типа соответствия. То есть сам знак + больше не учитывается во фразах, а при совпадении ключевого слова с модификатором и поискового запроса будет учитываться порядок слов.
С июля 2021 года больше нельзя будет создавать ключевые слова с модификаторами широкого соответствия, а при любых правках ключевых фраз, созданных с ним ранее, тип соответствия будет автоматически меняться на фразовое.
Это изменение затронуло уже некоторые языки, в том числе русский, остальных оно коснется в ближайшее время.
Давайте разберем, как Google объясняет работу обновленного фразового типа соответствия.
Ключ с фразовым соответствием «перевозки из Москвы в Хабаровск», как и раньше, будет охватывать такие поисковые запросы, как «доступные перевозки из Москвы в Хабаровск».
Обратите внимание: новое слово доступные стоит до ключа «перевозки из Москвы в Хабаровск» — это стандартный принцип работы фразового соответствия. Также будут охватываться поисковые запросы, которые раньше учитывались только при наличии модификатора широкого соответствия, например, «Москва профессиональные перевозки в Хабаровск»
Здесь порядок слов ключевой фразы изменился, слово профессиональные стоит внутри фразы. Такой вариант допускал модификатор широкого соответствия
Также будут охватываться поисковые запросы, которые раньше учитывались только при наличии модификатора широкого соответствия, например, «Москва профессиональные перевозки в Хабаровск». Здесь порядок слов ключевой фразы изменился, слово профессиональные стоит внутри фразы. Такой вариант допускал модификатор широкого соответствия.
При фразовом соответствии объявления не будут показываться по запросам, в которых используется обратный порядок слов (например, тем, кому нужны перевозки «из Хабаровска в Москву»).
Это изменение увеличит охват ключей с фразовым соответствием. В частности, это произойдет, так как порядок слов будет учитываться только при совпадении ключа и поискового запроса по смыслу. В остальных случаях добавится, по сути, новый вариант ключевого слова.
Поэтому надо не забывать следить за поисковыми запросами и регулярно обновлять минус-слова. И если в ваших кампаниях все еще остались ключевые фразы с модификатором широкого соответствия, то трафик по ним будет постепенно снижаться.
По заверению Google, никакие правки в текущие ключевые слова с фразовым соответствием или модификаторами широкого соответствия не нужно вносить: все изменения автоматически вступили в силу. А изменения фразового соответствия и модификаторов широкого соответствия не повлияют на типы соответствия минус-слов.
Влияние
Первоначальная мотивация для GFT заключалась в том, что возможность раннего определения активности заболевания и быстрого реагирования может снизить воздействие сезонного и пандемического гриппа. В одном из отчетов говорилось, что Google Flu Trends может предсказать региональные вспышки гриппа за 10 дней до того, как о них сообщит CDC (Центры по контролю и профилактике заболеваний).
в Пандемия гриппа 2009 г. Google Flu Trends отслеживает информацию о гриппе в США. В феврале 2010 г. CDC выявил резкое увеличение случаев гриппа в центрально-атлантическом регионе США. Однако данные Google по поисковым запросам о симптомах гриппа смогли показать такой же всплеск за две недели до публикации отчета CDC.
«Чем раньше будет предупреждение, тем раньше можно будет принять меры профилактики и контроля, и это может предотвратить случаи гриппа», — сказала д-р Лин Финелли, руководитель отдела эпиднадзора в отделении CDC по гриппу. «От 5 до 20 процентов населения страны ежегодно заболевают гриппом, что в среднем приводит к 36 000 смертей».
Google Flu Trends — это пример коллективный разум которые можно использовать для определения тенденций и расчета прогнозов. Данные, собираемые поисковыми системами, очень полезны, потому что поисковые запросы отражают неотфильтрованные желания и потребности людей. «Это кажется действительно умным способом использования данных, которые непреднамеренно создаются пользователями Google, чтобы увидеть закономерности в мире, которые в противном случае были бы невидимы», — сказал Томас У. Мэлоун, профессор школы менеджмента Sloan при Массачусетском технологическом институте. «Я думаю, что мы просто касаемся того, что возможно с коллективным разумом».
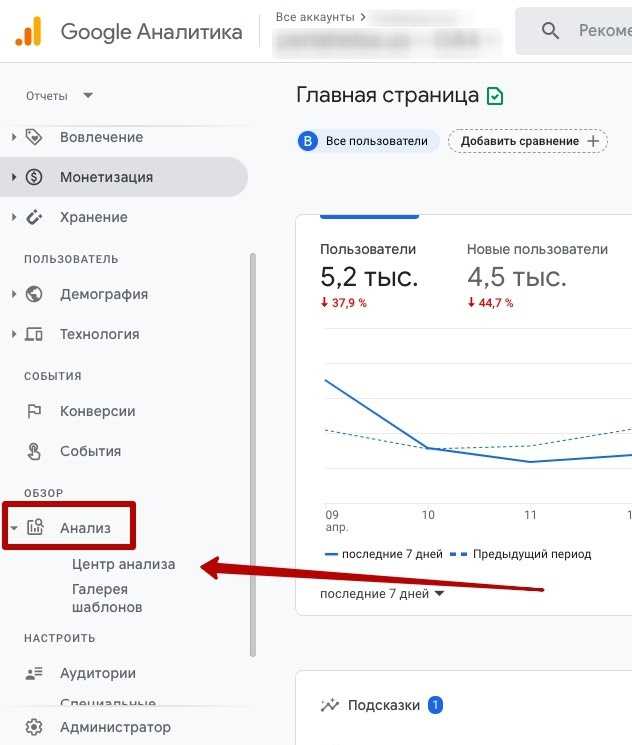
Найди потерянное, ограничь подозрительное
В разделе «Безопасность и вход» можно усилить безопасность своего аккаунта; сменить пароль и резервную почту; по подсказкам поэтапно найти потерянный телефон, на котором используется ваш аккаунт, а если девайс на платформе Android, его можно заблокировать и написать сообщение нашедшему.
![]()
Скриншот myaccount.google.com
![]()
безопасности находится переключатель, который отвечает за автоматическую блокировку ненадёжных приложений, также можно провести ревизию вручную в подразделе «Приложения, у которых есть доступ к аккаунту». Если нажать на любые приложения в появившемся списке, развернётся подробная информация, какие привилегии имеет программа. Стоит внимательнее посмотреть список и отключить то, чем давно не пользуетесь либо чему не доверяете.
![]()
Скриншот myaccount.google.com
Проблемы конфиденциальности
Google Flu Trends пытается избежать нарушений конфиденциальности, собирая только миллионы анонимных поисковых запросов, не идентифицируя лиц, выполнивших поиск. Их журнал поиска содержит IP-адрес пользователя, который можно использовать для отслеживания региона, в котором изначально был отправлен поисковый запрос. Google запускает программы на компьютерах для доступа к данным и их вычисления, поэтому в этом процессе не участвует человек. Google также внедрил политику анонимности IP-адреса в своих журналах поиска через 9 месяцев.
Тем не менее, Google Flu Trends вызвал обеспокоенность по поводу конфиденциальности среди некоторых групп конфиденциальности. В 2008 году Центр электронной информации о конфиденциальности и Права пациента на конфиденциальность отправили письмо Эрику Шмидту , тогдашнему генеральному директору Google. Они признали, что использование данных, созданных пользователями, может существенно поддержать усилия общественного здравоохранения, но выразили обеспокоенность тем, что «расследования конкретных пользователей могут быть инициированы, даже несмотря на возражения Google, по решению суда или президентских властей».
Важность факторов E-A-T для SEO
Опыт, доверие, экспертность — то, к чему мы должны стремиться в профессиональной сфере
Исходя из рекомендаций Google по оценке качества, это важно и для поисковой оптимизации
Поисковая система определяет назначение страницы. Сайты или страницы, которые распространяют ненависть, вредят, дезинформируют или обманывают пользователей, должны получить самую низкую оценку.

Google выделил факторы E-A-T — expertise, authoritativeness, trustworthiness— экспертность, авторитет и достоверность
Это значит, что для поисковика важно:
- опыт автора контента;
- авторитетность создателя контента и сайта, где он опубликован;
- надежность автора, контента и сайта.
Высокий уровень E-A-T может быть у страниц и сайтов всех типов, даже у онлайн-журналов со сплетнями, порталов о моде и юморе, новостных сайтов. Сайты о хобби, к примеру, фотографии или игре на гитаре, также требуют опыта. Некоторую информацию можно найти только на форумах в обсуждениях, где сообщество экспертов предоставляет ценные мнения по конкретным темам.
Особенно E-A-T важны для сайтов категории YMYL — Your Money or Your Life — связанных со здоровьем, финансами и благополучием пользователей. Это довольно обширная сфера, туда можно отнести медицинские, финансовые, юридические, налоговые сайты, и даже порталы, посвященные ремонту и воспитанию детей. Такой контент должен быть написан экспертами в теме и быть размещен на авторитетных источниках.
Медицинские рекомендации должны быть подготовлены людьми или организациями, имеющими соответствующее медицинское образование, их нужно регулярно редактировать, пересматривать и обновлять.
Новостные статьи с высоким рейтингом E-A-T должны быть подготовлены с журналистским профессионализмом: они должны содержать фактически точный контент и быть написаны так, чтобы помочь пользователям лучше понять события. У новостных сайтов с высоким E-A-T обычно есть редакционная политика и выстроен алгоритм проверки фактов.
![]() Редакционная политика на сайте BBC
Редакционная политика на сайте BBC
Как E-A-T влияют на ранжирование
В Руководстве по оценке качества есть ценная информация о процессе ранжирования в Google, так что его полезно изучить для работы по сайту. Тем не менее, представители поисковика говорят, что E-A-T не является фактором ранжирования.
Экспертность, авторитет и доверие — абстрактные понятия. По словам представителя Google Дэнни Салливана, E-A-T сам по себе не является фактором ранжирования в том смысле, что E-A-T нельзя измерить, как скорость загрузки, и получить какое-то число. Но поисковик использует различные сигналы в качестве прокси, чтобы определить, соответствует ли контент принципам E-A-T, многие алгоритмы нацелены на определение составляющих E-A-T.
Опыт, авторитет и надежность сложно интерпретировать алгоритмами поиска, которые понимают только код. Похоже, что сейчас у Google нет надежного способа преобразовать эти сигналы в рейтинг, кроме как смотреть оценки асессоров перед каждым обновлением алгоритма. Есть две проблемы:
- Непонятно, кто именно будет определять эти сигналы, как их измерять, в соответствии с каким стандартом.
- Введение таких факторов создает систему, в которой мелкие и новые сайты проигрывают крупным, потому что просто не успевают завоевать доверие.
Решение этих проблем требует времени и усилий со стороны поисковой системы. Пока E-A-T не является фактором ранжирования, и мы не знаем, станет ли он им в будущем.
Тем не менее, но на практике можно наблюдать, что сайты из категории YMYL без опыта и авторитета ранжируются хуже. К примеру, почти на всех сайтах медицинских клиник, которые занимаются своим продвижением и находятся на первой странице выдачи, размещены статьи, проверенные или даже написанные врачом.
Параметры E-A-T не должны быть приоритетнее традиционных задач SEO — создания ссылок и технической оптимизации. Но сами по себе они полезны, поскольку побуждают делать достоверный и полезный контент и работать над доверием к площадке и экспертам, которые на ней публикуются.
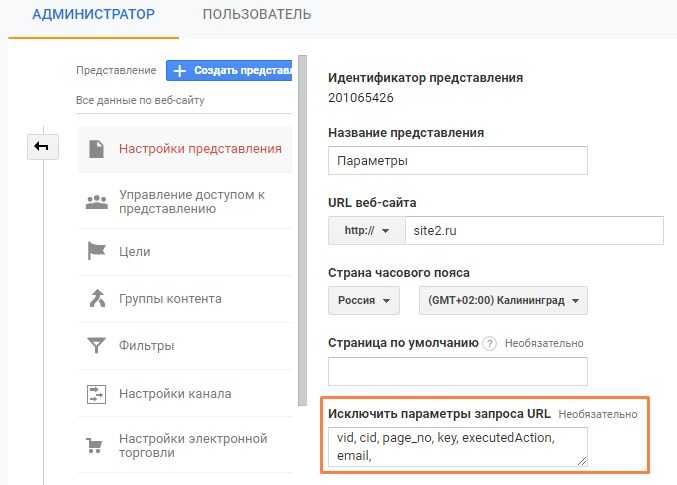
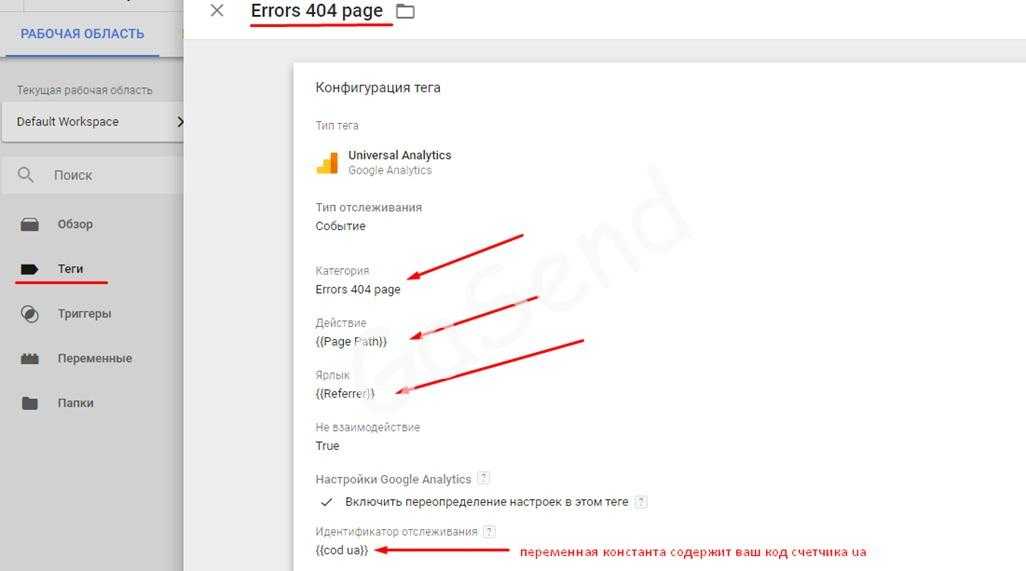
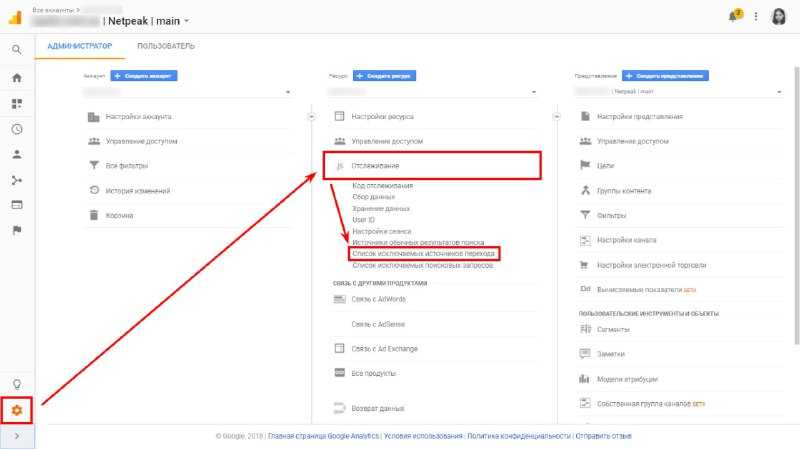
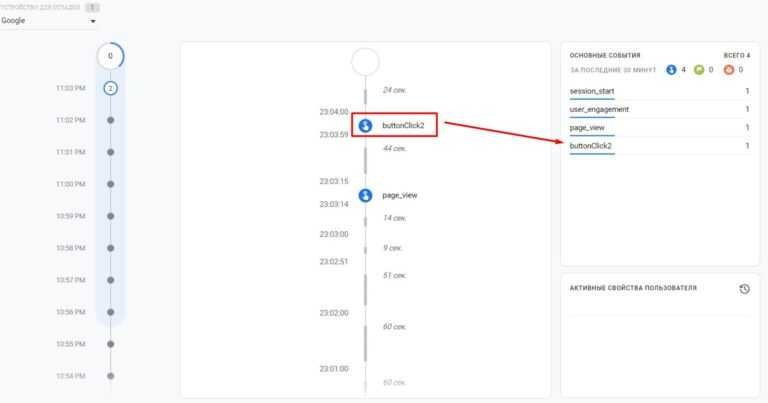
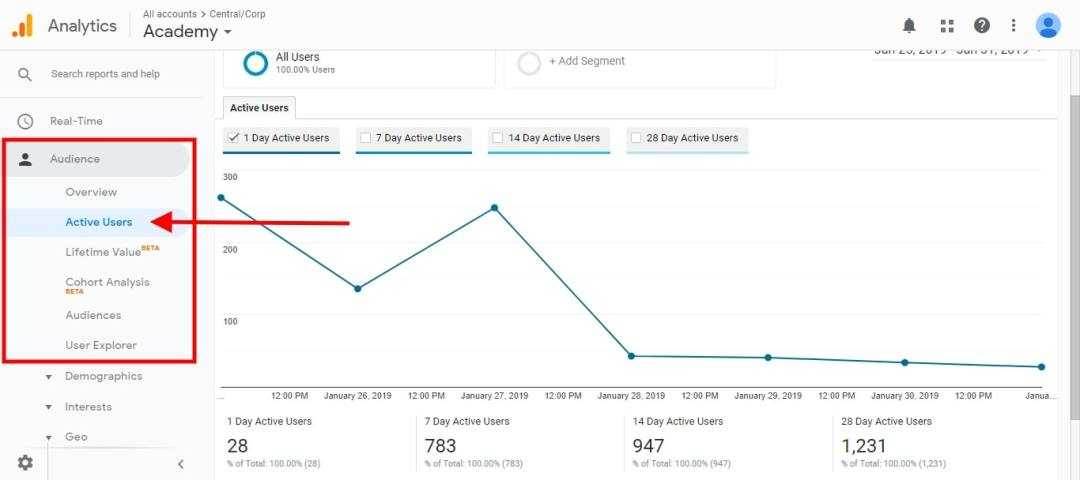
Ошибки в настройке событий и целей
8. Код трекинга событий не соответствует коду счетчика GA
Есть три типа скриптов отслеживания Google Аналитики:
- ga.js (устаревший код);
- analytics.js (самый удобный и распространенный);
- gtag.js (самый свежий, с расширенными возможностями для профессионалов).
Чтобы данные по взаимодействию с сайтом отслеживались корректно, код событий должен соответствовать коду счетчика. Например, если у вас установлен счетчик GA с помощью кода ga.js, а вы добавляете событие с помощью трекинг-кода для analytics.js – события не будут отображаться в отчетах.
В некоторых случаях нужно отправлять события без взаимодействия. Например, у вас на главной есть видео и настроено событие на нажатие кнопки «Play». По умолчанию, если пользователь запустит видео, а затем уйдет с сайта, этот уход не будет учтен как отказ (так как запуск видео фиксируется как событие).
Для справки. Отказом считается сеанс, в течение которого было выполнено только одно взаимодействие. По умолчанию событие считается взаимодействием и тоже учитывается при подсчете показателя отказов.
![Google flu trends содержание а также история [ править ]](https://sariola.ru/wp-content/uploads/d/e/f/defdc59277353a6ab821a40f77475415.jpeg)
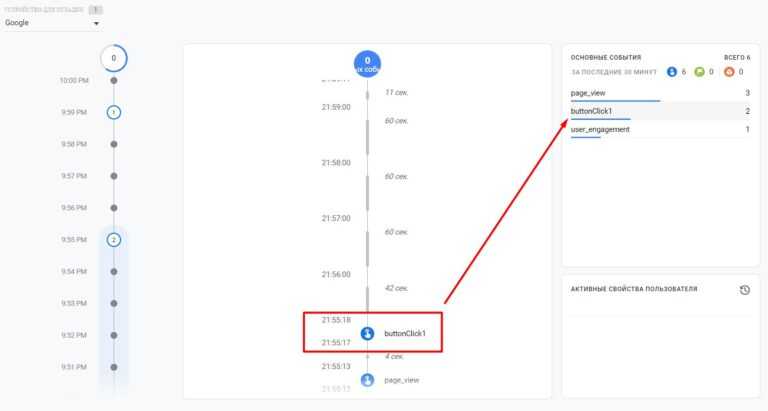
Если же вы хотите, чтобы событие «Проигрывание видео» не влияло на расчет показателя отказов, при настройке события вам нужно добавить в код события параметр nonInteraction и присвоить ему значение true.
Пример кода:
ga(‘send’, ‘event’, ‘Videos’, ‘play’, ‘Fall Campaign’, {
nonInteraction: true
});
В этом случае при проигрывании видео событие будет передаваться в Google Аналитику, но не будет учитываться как взаимодействие. Соответственно, не повлияет на расчет показателя отказов.
10. Не настроены отдельные цели под мобильный сайт
Если у вас развернута мобильная версия сайта на мобильном поддомене (m.site.ru) – не забудьте настроить отдельные цели для нее.
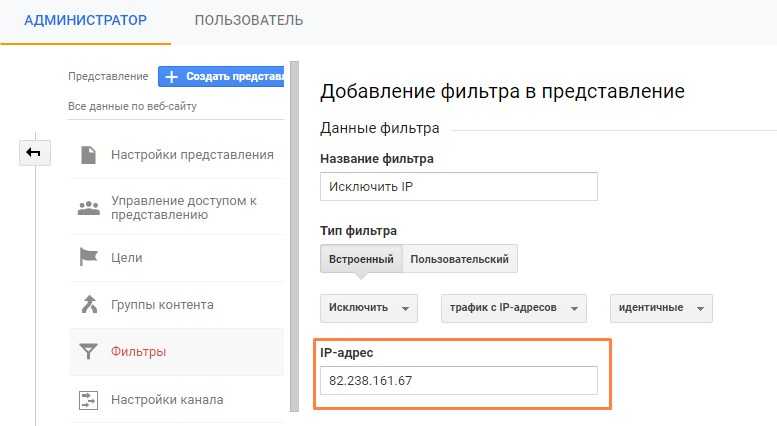
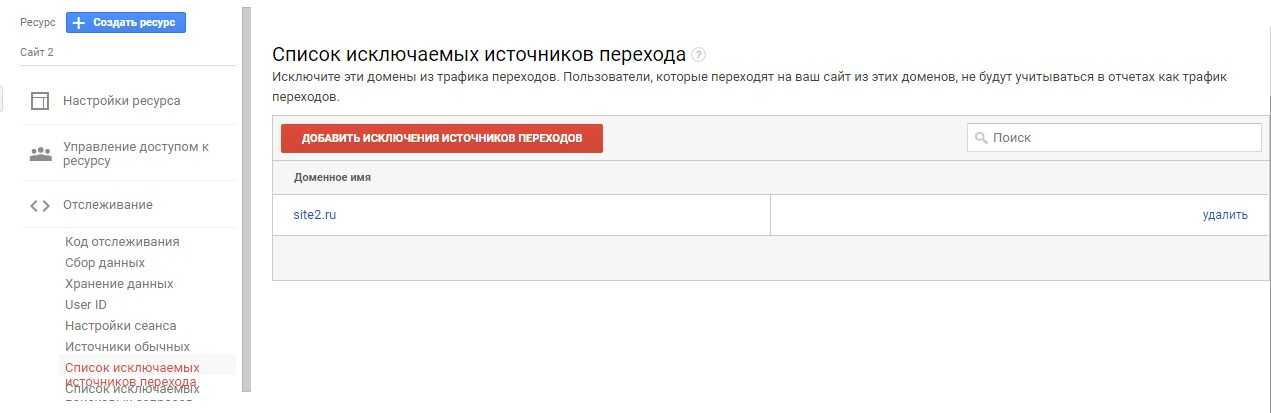
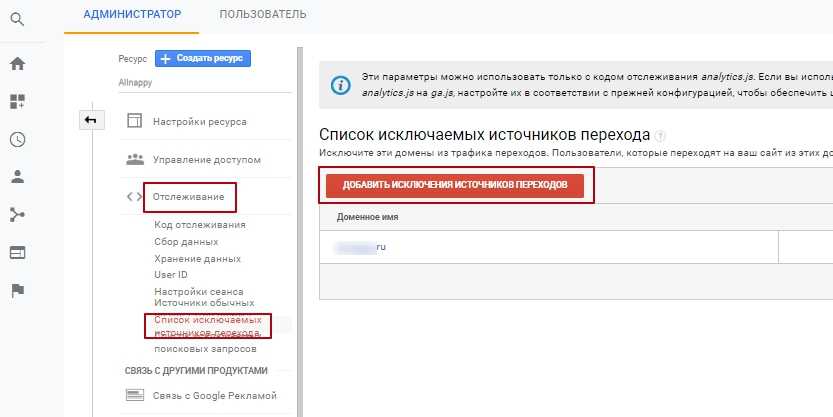
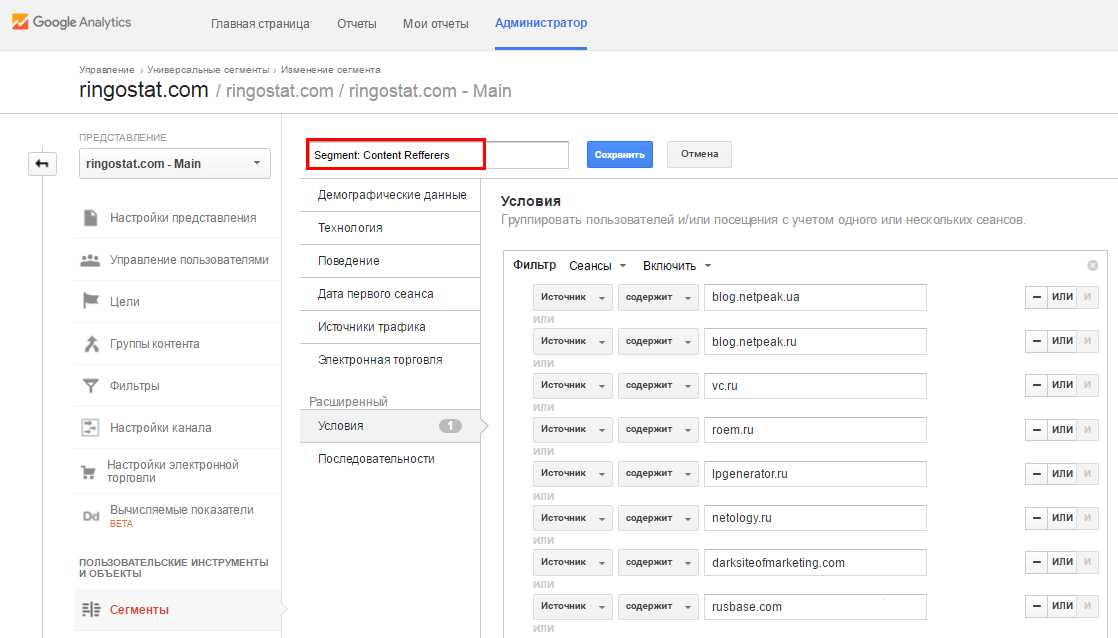
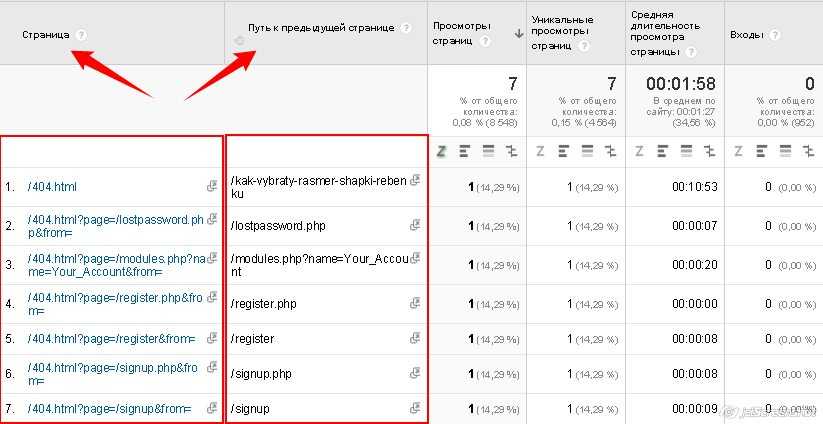
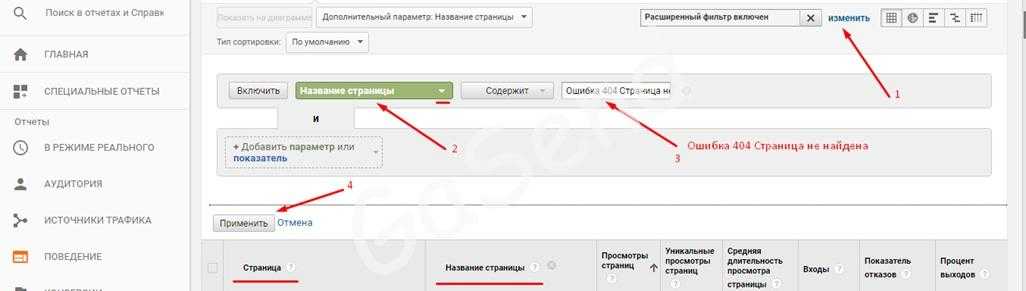
Не объединять одни и те же источники трафика
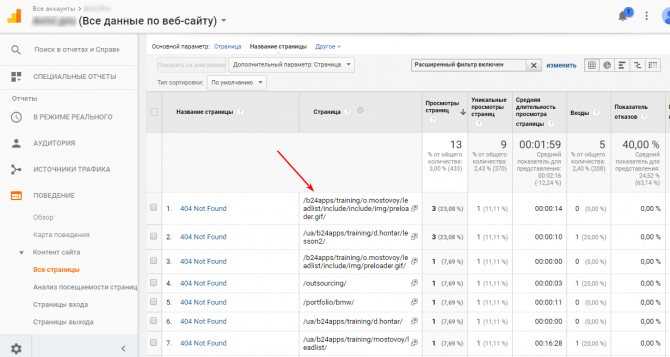
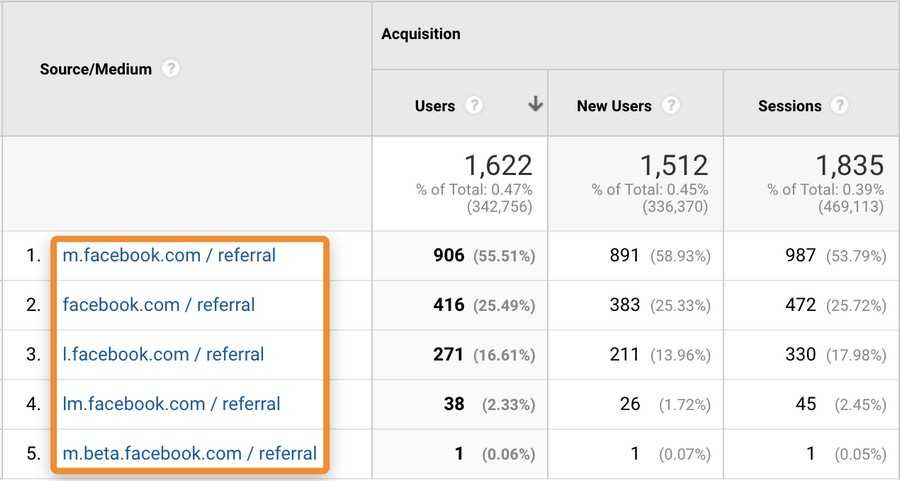
Некоторые из каналов трафика повторяются, потому что система распознает их как разные источники. Частый пример — реферальный трафик с Facebook:
![]() Повторяющиеся источники, скриншот ahrefs.com
Повторяющиеся источники, скриншот ahrefs.com
Эти реферальные ссылки Facebook использует в целях безопасности и конфиденциальности, но они усложняют аналитику трафика по источникам.
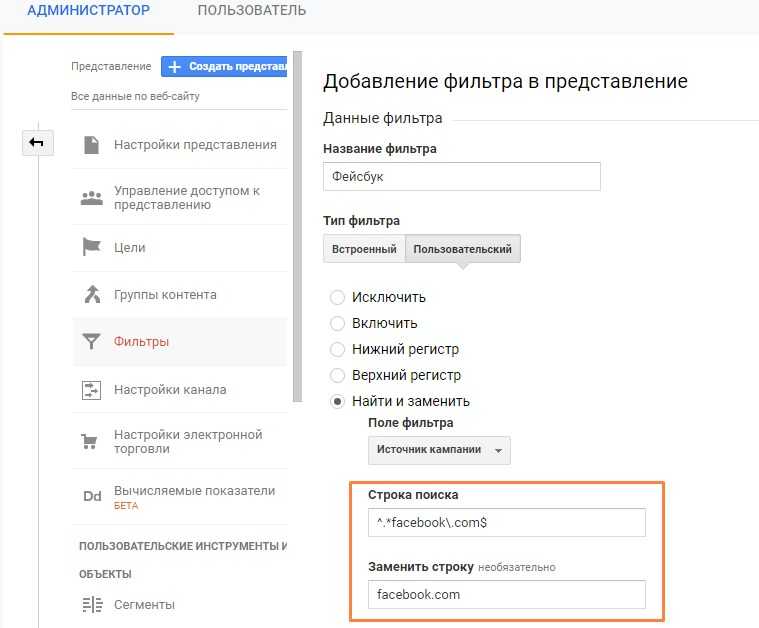
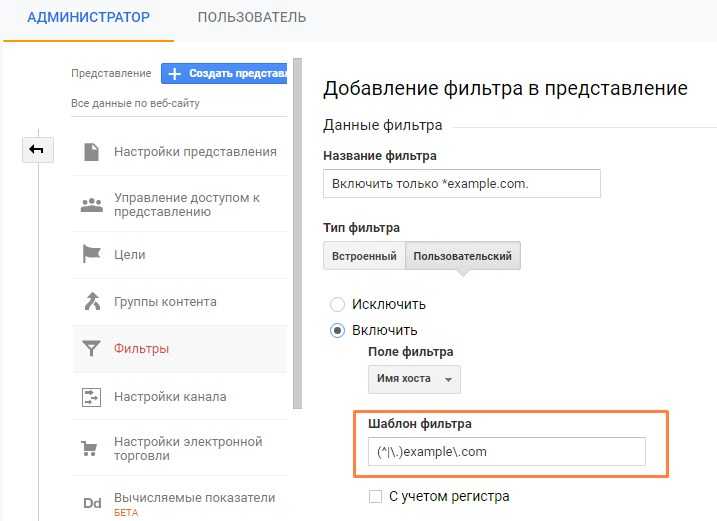
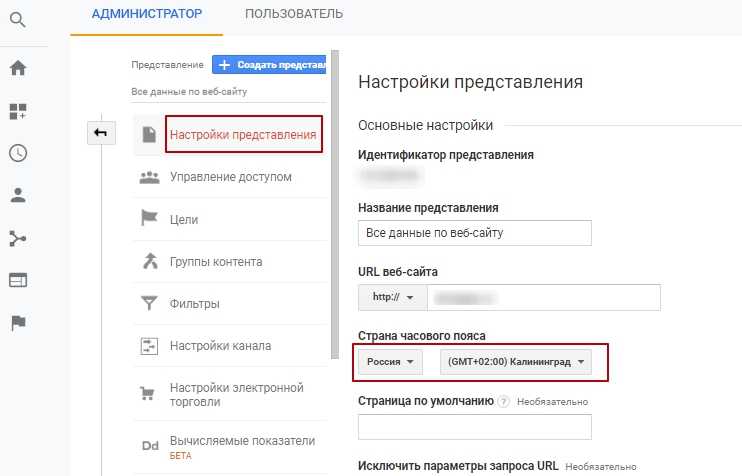
Это можно исправить фильтрами, этот объединяет реферальный трафик с разных каналов, относящихся к Facebook:
![]() Настройка фильтра
Настройка фильтра
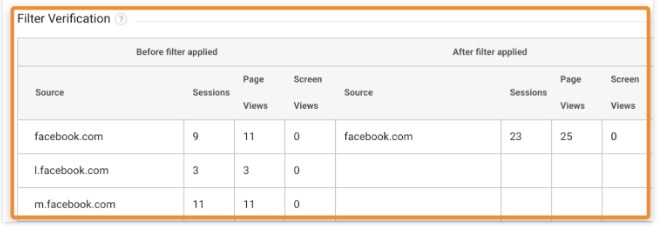
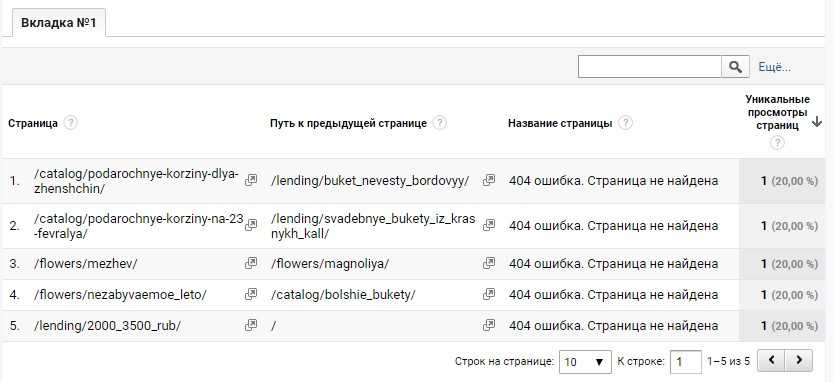
Ниже есть проверка фильтра, убедитесь, что он работает правильно:
![]() Работа фильтра, скриншот ahrefs.com
Работа фильтра, скриншот ahrefs.com
Google Analytics не применяет фильтры задним числом, поэтому вам все равно придется иметь дело со старыми данными без объединения источников.
Проблемы конфиденциальности [ править ]
Google Flu Trends пытается избежать нарушений конфиденциальности, собирая только миллионы анонимных поисковых запросов, не идентифицируя лиц, выполнивших поиск. Их журнал поиска содержит IP-адрес пользователя, который можно использовать для отслеживания региона, в котором изначально был отправлен поисковый запрос. Google запускает программы на компьютерах для доступа к данным и их вычисления, поэтому в этом процессе не участвует человек. Google также внедрил политику анонимности IP-адреса в своих журналах поиска через 9 месяцев.
Тем не менее, Google Flu Trends вызвал обеспокоенность по поводу конфиденциальности среди некоторых групп конфиденциальности. В 2008 году Центр электронной информации о конфиденциальности и Права пациента на конфиденциальность отправили письмо Эрику Шмидту , тогдашнему генеральному директору Google. Они признали, что использование данных, созданных пользователями, может существенно поддержать усилия общественного здравоохранения, но выразили обеспокоенность тем, что «расследования конкретных пользователей могут быть инициированы, даже несмотря на возражения Google, по постановлению суда или властям президента».
Методы [ править ]
Согласно описанию Google Flu Trends, для сбора информации о тенденциях гриппа использовался следующий метод.
Во-первых, временной ряд вычисляется примерно для 50 миллионов общих запросов, вводимых еженедельно в Соединенных Штатах с 2003 по 2008 годы. Временные ряды запроса вычисляются отдельно для каждого состояния и нормализуются на долю путем деления количества каждого запроса на количество все запросы в этом состоянии. Путем определения IP-адреса, связанного с каждым поиском, можно определить состояние, в котором был введен этот запрос.
Линейная модель используется для вычисления логарифма шансов посещения врача гриппоподобным заболеванием (ГПЗ) и логарифма шансов поискового запроса, связанного с ГПЗ:
- логит(п)знак равноβ+β1×логит(Q)+ϵ{\ displaystyle \ operatorname {logit} (P) = \ beta _ {0} + \ beta _ {1} \ times \ operatorname {logit} (Q) + \ epsilon}
P — это процент посещений врача по ГПЗ, а Q — доля запросов, связанных с ГПЗ, вычисленная на предыдущих шагах. β — точка пересечения, β 1 — коэффициент, а ε — погрешность.
Каждый из 50 миллионов запросов проверяется как Q, чтобы увидеть, может ли результат, вычисленный из одного запроса, соответствовать фактическим историческим данным ILI, полученным из Центров по контролю и профилактике заболеваний США (CDC). Этот процесс создает список основных запросов, который дает наиболее точные прогнозы данных CDC ILI при использовании линейной модели. Затем выбираются 45 лучших запросов, поскольку при агрегировании эти запросы наиболее точно соответствуют данным истории. Используя сумму 45 самых популярных запросов, связанных с ILI, линейная модель подбирается к еженедельным данным ILI за период с 2003 по 2007 год, чтобы можно было получить коэффициент. Наконец, обученная модель используется для прогнозирования вспышки гриппа во всех регионах США.
Впоследствии этот алгоритм был пересмотрен Google, частично в ответ на озабоченность по поводу точности, и попытки воспроизвести его результаты показали, что разработчики алгоритма «почувствовали неявную потребность скрыть фактические выявленные поисковые запросы».
Как выполняется нормализация данных Google Trends?
Google Trends нормализует полученные данные для удобства сравнения поисковых запросов. Сведения нормализуются с учетом времени и места отправки запроса. Это делается следующим образом:
-
Каждый элемент данных делится на общее число поисковых запросов в конкретном регионе за определенное время, что позволяет получить представление об их относительной популярности. В противном случае на первых местах всегда были бы регионы, пользователи из которых активнее всего осуществляют поиск в Google.
-
Полученные результаты ранжируются по стобалльной шкале в соответствии с отношением той или иной темы ко всем запросам по всем темам.
-
В регионах, где определенная тема пользуется примерно одинаковой популярностью, общее количество запросов может быть разным.
Почему слежка Google опасна
Ограничивать данные, которые по умолчанию собирает Google, следует хотя бы потому, что ваша личная информация может попасть в чужие руки. И не только, если кто-то взломает аккаунт.
Вашу информацию могут слить в Сеть. По вашей же вине
Так, в июле поисковик «Яндекс» проиндексировал файлы с сервиса Google Docs, не защищенные настройками приватности. В результате в публичном доступе оказались документы, в том числе персональные данные, пароли и другая конфиденциальная информация, занесенная в файлы Google Docs. Первое, что нашли пользователи через поиск «Яндекса», — это пароли. В открытом доступе оказались пароли к личным и рабочим аккаунтам в соцсетях, к электронной почте и другим сервисам. Кроме того, в документах обнаружились номера электронных кошельков. Впрочем, все защищенные паролем документы в поисковой выдаче не появились. Утечка произошла из-за халатности самих пользователей.
Вашу информацию могут передать посторонним людям. Совершенно законно
В пользовательском соглашении четко прописано, кому Google может сливать вашу конфиденциальную информацию:
- Частным компаниям, если вы дали на это согласие. Пример от Google: «Если Вы с помощью Google Home обратились в сервис вызова водителя, мы предоставим Ваш адрес этому сервису только с Вашего разрешения».
- Аффилированным лицам Google и иным доверенным компаниям и лицам для обработки от имени Google.
- Правоохранительным органам, силовикам, ФСБ.
- Издателям, рекламодателям, разработчикам. Пример от Google: «Мы предоставляем эту информацию для того, чтобы пользователи могли изучать тенденции использования наших сервисов. Кроме того, мы разрешаем отдельным партнерам собирать информацию из вашего браузера или устройства с помощью собственных файлов cookie и иных технологий и использовать ее для показа рекламы и оценки ее эффективности».
Точность
В первоначальном документе Google говорилось, что прогнозы Google Flu Trends были на 97% точны по сравнению с данными CDC. Однако в последующих отчетах утверждалось, что прогнозы Google Flu Trends иногда были очень неточными, особенно в период 2011–2013 годов, когда он постоянно завышал относительную заболеваемость гриппом, и более одного интервала в сезоне гриппа 2012–2013 гг. прогнозировалось в два раза больше посещений врачей, чем записал CDC.
Одним из источников проблем является то, что люди, выполняющие поиск в Google по гриппу, могут очень мало знать о том, как диагностировать грипп; поиски симптомов гриппа или гриппа вполне могут быть исследованием симптомов заболевания, которые похожи на грипп, но на самом деле не грипп. Кроме того, анализ поисковых запросов, которые, как сообщается, отслеживаются Google, таких как «лихорадка» и «кашель», а также влияние изменений в их алгоритме поиска с течением времени, вызвали озабоченность по поводу значения его прогнозов. Осенью 2013 года Google начал попытки компенсировать рост поисковых запросов из-за того, что в новостях упоминалось о гриппе, что ранее приводило к искажению результатов. Однако один из анализов пришел к выводу, что «комбинируя GFT и запаздывающие данные CDC, а также динамически перекалибруя GFT, мы можем существенно улучшить производительность GFT или только CDC». Более позднее исследование также демонстрирует, что данные поиска Google действительно можно использовать для улучшения оценок, уменьшая количество ошибок, обнаруженных в модели, использующей только данные CDC, на 52,7%.
Переоценив исходную модель GFT, исследователи обнаружили, что модель агрегирует запросы о различных состояниях здоровья, что может привести к завышенному прогнозированию показателей ГПЗ; В той же работе был предложен ряд более продвинутых линейных и нелинейных более эффективных подходов к моделированию ИЛИ.
Просмотр ответов
Просмотр ответов на определенный вопрос
- Откройте файл в Google Формах.
- Нажмите Ответы в верхней части формы.
- Выберите Сводка.
Просмотр ответов отдельных пользователей
Вы можете посмотреть ответы конкретного пользователя или каждую отправленную им версию ответов, если разрешено повторное заполнение формы.
- Откройте файл в Google Формах.
- Нажмите Ответы в верхней части формы.
- Выберите Отдельный пользователь.
- Чтобы переключаться между ответами, нажимайте на значок «Предыдущий» или «Следующий» .
Примечание. Чтобы выбрать ответ из списка, нажмите на стрелку вниз .
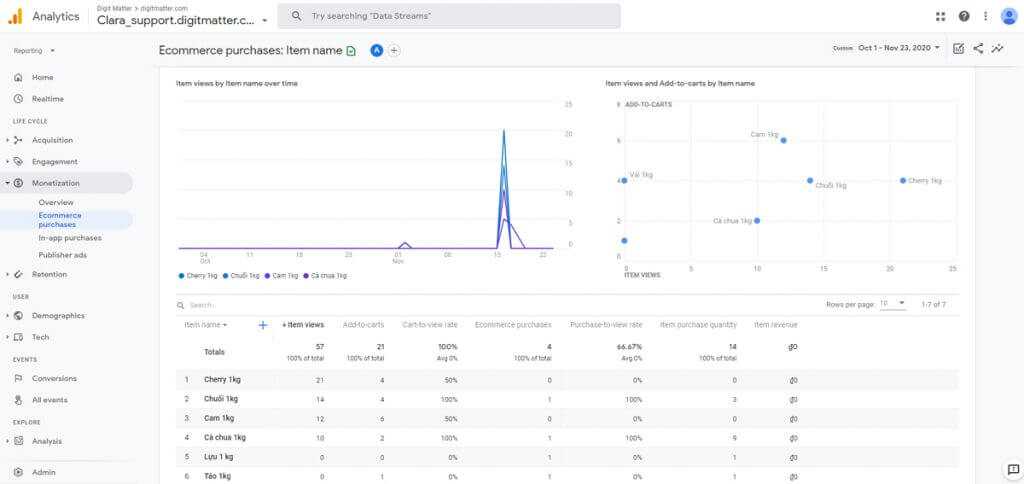
Просмотр ответов в виде таблицы
Выполните следующие действия:
- Откройте файл в Google Формах.
- Нажмите Ответы в верхней части формы.
- В правом верхнем углу нажмите на значок «Создать таблицу» .
Скачивание в формате CSV
- Откройте файл в Google Формах.
- Нажмите Ответы в верхней части формы.
- Нажмите «Ещё» Скачать ответы (CSV).
История
Идея Google Flu Trends заключалась в том, что, отслеживая поведение миллионов пользователей в Интернете, можно проанализировать большое количество собранных поисковых запросов Google, чтобы выявить наличие у населения гриппоподобных заболеваний. Google Flu Trends сравнил эти результаты с историческим исходным уровнем активности гриппа для соответствующего региона, а затем сообщает об уровне активности как минимальном, низком, умеренном, высоком или интенсивном. Эти оценки в целом согласуются с традиционными данными эпиднадзора, собранными учреждениями здравоохранения как на национальном, так и на региональном уровне.
Рони Зейгер участвовал в разработке Google Flu Trends.