
Зачем потребовалась интеграция Arenadata и Visiology?
Подходов к работе BI-систем на сегодняшний день несколько. Но когда речь идет о больших данных для самых разных задач, обычно используется ROLAP. Работает он достаточно просто: когда пользователь нажимает что-то на дашборде, например, выбирает какой-то фильтр, внутри платформы формируется SQL-запрос, который уходит на тот или иной бэкэнд. В принципе, под системой BI может лежать любая СУБД, которая поддерживает запросы — от Postgres до Teradata. Подробнее о схемах работы OLAP я рассказывал здесь.
Преимущество интеграции BI с СУБД заключается в том, что для работы системы, по сути, нет ограничения по объему данных. Но при этом падает скорость выполнения запросов — конечно, если не использовать специализированную колоночную СУБД, например, ClickHouse или Vertica. И, хотя у ClickHouse спектр возможностей пока еще уже, чем у той же Vertica, система развивается и выглядит очень многообещающей.
Но даже с колоночной СУБД есть свои минусы при работе с BI, и самый первый из них — это более низкая эффективность использования кэша на уровне платформы в целом, потому что СУБД, в отличие от самой BI-платформы, «не знает» многого о поведении пользователей и не может использовать эту информацию для оптимизации. Когда большое количество пользователей начинают работать, по-разному делать запросы и обращаться к дашбордам, требования к железу, на котором крутится СУБД — даже хорошая, аналитическая и колоночная — могут оказаться очень серьезными.
Второй момент — это ограничение аналитической функциональности: все, что не укладывается в SQL-запрос, поддерживаемый распределенной СУБД, отсекается автоматически (например, в случае ClickHouse — это оконные функции). И этопроблема, потому что в BI есть много вещей, которые с трудом транслируются в SQL-запросы или выполняются неоптимально.
Второй вариант — это In-memory OLAP. Он подразумевает перенос всех обрабатываемых данных в специальный движок, который молниеносно прорабатывает базу в 200-300 Гб — это порядок единицы миллиардов записей. Кстати, подробнее про ограничения In-Memory OLAP я уже рассказывал здесь. На практике встречаются инсталляции In-Memory OLAP, укомплектованные 1-2-3 терабайтами оперативной памяти, но это скорее экзотика, причем дорогостоящая.
Практика показывает, что далеко не всегда можно обойтись тем или иным подходом. Когда требуются одновременно гибкость, возможность работы с большим объемом данных и поддержка значительного количества пользователей, возникает потребность в гибридной системе, которая с одной стороны загружает данные в движок In-Memory OLAP, а с другой — постоянно подтягивает нужные записи из СУБД. В этом случае движок OLAP используется для доступа ко всему массиву данных, без всяких задержек. И в отличие от чистого In-Memory OLAP, который нужно периодически перезагружать, в гибридной модели мы всегда получаем актуальные данные.
Такое разделение данных на “горячие” и “холодные” объединяет плюсы обоих подходов — ROLAP и In-Memory, но усложняет проект внедрения BI. Например, разделение данных происходит вручную, на уровне ETL процедур. Поэтому для эффективной работы всего комплекса очень важна совместимость между бэкэндом и самой BI-системой. При том, что SQL-запросы остаются стандартными, в реальности всегда есть аспекты их выполнения, нюансы производительности.
Не верьте агентствам
Когда мы определились с планом измерений, стали искать способы реализации. На тот момент мы не особенно представляли себе рамки проекта и планировали, что автоматизацией займёмся позже. На нас давили стейкхолдеры, которые хотели получать отчёты по всем источникам в одном документе ежемесячно.
Мы решили сделать «быстрый фикс» только для одного общего дэшборда — заказать в агентстве шаблон отчета в .ppt и связать его с экселевской таблицей.
Для работ было выбрано агентство, с которым у компании давно сложились хорошие рабочие отношения. Менеджеры агентства убедили нас, что они в состоянии справиться с такой задачей, и мы начали. Конечно, всё полетело к чертям.
Во-первых, делать связку презентации и Excel не было смысла: на рынке давно уже есть сервисы визуализации типа Data Studio или Power Bi. Мы это знали, но агентство убедило нас, что .ppt + .xls будет быстрее. Тут бы нам обсудить ситуацию со стейкхолдерами, чтобы снизить давление от них, сдвинуть дедлайн и реализовать всё на готовом решении, но мы же лёгких путей не ищем. Поэтому согласились на Excel и презентацию.
Во-вторых, делать дизайн дэшбордов — это совсем не то же самое, что делать дизайн сайта или инфографику. Мы потратили около двух месяцев, чтобы добиться результата, на который можно было смотреть без ужаса. Да, этот шаблон нам потом помог, когда мы наконец занялись автоматизацией дэшбордов в Data Studio. Но можно было обойтись и без извращений.
В итоге мы завершили отношения с агентством и принялись искать подрядчиков, чтобы сделать проект по уму. Тут мы уже были биты жизнью и очень подробно расспрашивали про опыт по визуализации данных именно из наших источников.
Начали проект почти с чистого листа с датским агентством. В команду вошли менеджер проекта, data scientist, программист, dashboard-специалист и ещё один или два человека any key.
Как обычно, агентство было слишком оптимистично по срокам, но я заранее отложила дату официального завершения проекта на месяц, 61 дэшборд всё-таки. Так и вышло, закончили как раз к этому самому «сдвинутому» дедлайну.
Самым муторным был этап проверки качества
В таких проектах важно не только, чтобы циферки были правильные из нужных источников, но и чтобы финальные дэшборды совпадали со спецификацией. Учитывая, что на одном слайде дэшборда для разных графиков могут быть разные источники (например, разные представления из Google Analytics), пропустить такую ошибку проще простого
Преимущества и недостатки Google Data Studio
Сервис экономит время и закрывает большинство потребностей вебмастера, но минусы у него тоже имеются. Собрали главные преимущества и недостатки, чтобы новички видели полную картину.
| Плюсы | Минусы |
|
1. До 2016 года у сервиса были жёсткие ограничения в бесплатной версии, но теперь их нет.2. Простой интерфейс. Разобраться в особенностях создания отчётов можно за несколько часов.3. Большой выбор инструментов. Загрузка данных из разных источников, объединение статистики, вычисляемые показатели на основе формул. 4. Автоматическое обновление данных. В отчётах представлены только актуальные цифры.5. Гибкость. Элементы собираются в конструкторе. Легко изменить блоки под себя, добавить новые или удалить.6. История изменений. Легко понять, когда и кем были внесены правки в отчёт и, в случае необходимости, сделать откат до нужной версии. |
1. Зависимость от интернета. Google Data Studio — это онлайн-сервис, поэтому без доступа к сети работать в нём не получится.2. Нагрузка на систему. Файлы с большим количеством данных сильно нагружают компьютер. Браузер периодически зависает в момент обновления данных.3. Нет адаптивности под мобильные устройства. Собирать большие отчёты со смартфона никто не будет, но вот простенькие графики было бы удобно строить.4. Внутренние ограничения. Можно добавить не более 5 источников данных в одну визуализацию и не больше 10 условий в фильтр. |
RAWGraphs
RAWGraphs
Сильные стороны бесплатной версии
- Диаграммы в RAWGraphs очень просто создавать, для работы с системой не нужно даже регистрировать учётную запись.
- Система поддерживает различные форматы входных данных — TSV, CSV, DSV, JSON и Excel-файлы(.xls, .xlsx).
- По сведениям RAWGraphs обработка данных производится исключительно средствами браузера. Платформа не занимается серверной обработкой или хранением данных. Никто из тех, кто не имеет отношения к данным, не сможет их просматривать, модифицировать или копировать.
- RAWGraphs — это система, поддающаяся расширению. Например, добавлять в неё новые диаграммы можно, обладая базовыми знаниями D3.js.
Слабые стороны бесплатной версии
- Диаграммы, создаваемые в RAWGraphs, иногда выглядят слишком простыми. У пользователей системы есть не особенно много механизмов для подстройки их под свои нужды.
- Визуализации данных не являются интерактивными.
Что нужно помнить при выборе аналитической платформы
Важно смотреть не только на инструмент визуализации, но и на подсистему хранения и обработки данных. Решение от единого поставщика обеспечит более стабильную и эффективную работу.
Выбирайте готовую платформу от надежного вендора с широкой партнерской экосистемой
С внедрением и первичной настройкой поможет партнер-интегратор, а последующее развитие и поддержка может происходить силами заказчика или другого партнера.
Продумайте, кто и как будет пользоваться аналитикой. Сложность инструмента зачастую противоречит массовости внедрения. Обратитесь к сервисам, где рядовые сотрудники без специальных навыков смогут полноценно работать с отчетами и визуализациями и самостоятельно дорабатывать их при необходимости.
Не стоит гнаться за экзотичностью новых инструментов, маркетинговыми обещаниями, количеством возможных фичей и типов графиков. Примеряйте решение на вашу задачу, не стремитесь за максимальным функционалом. Как показывает практика, для задач бизнес-аналитики наиболее востребованными и понятными являются привычные столбчатые и линейные визуализации, табличные формы. Работу со сложной инфографикой лучше передать дизайнерам.
Параметры для событий
-
Задача. Размечаем сайт самостоятельно через GTM. Обнаружили ошибку, быстро ее исправили, но события с ошибкой продолжают поступать в GA.Решение. Чтобы оперативно найти корень проблемы, можно с каждым событием передавать CD:
Название контейнера (если их несколько на сайте) — встроенная переменная GTM;
Версию контейнера — встроенная переменная GTM;
Название тега — нужно настроить самостоятельно.
Передавать три эти параметра можно через какой-либо разделитель в переменной с типом “Константа”:
Область действия параметра — хит.Результат. С помощью настроенной переменной выяснили, что у некоторых пользователей осталась старая версия контейнера, поэтому события продолжают отправляться. Скорее всего пользователи просто не обновили страницу или она закешировалась, поэтому нужно немного подождать. -
Задача. Размечаем сайт через разработчиков. Они внедрили новую, написанную нами, инструкцию. После проверки оказалось, что некоторые события отправляются с ошибкой.Решение. Будем разделять события на новые/некорректно работающие и верно размеченные. Первые можно помечать, как test, вторые — prod.
Для этого пусть разработчики добавляют данные в dataLayer, а мы будем доставать их и отправлять в GA. Любой пуш будет выглядеть следующим образом:
где в двойных фигурных скобках заключены названия переменных, в которых хранятся данные на стороне разработчиков.
Нам понадобится создать переменную “Таблица поиска” (Lookup Table) для разделения событий:
`event_id` — переменная, которая достает из DataLayer идентификатор события.
Ставим галочку напротив “Установить значение по умолчанию” и в графе “Значение по умолчанию” пишем test. Таким образом изначально для всех событий эта переменная будет равна test. Убедившись, что событие размечено корректно, добавьте его event_id в ячейку “Входные данные”. В поле “Результат” пришем prod.
Так мы разделили все события на корректно размеченные и на новые/некорректно размеченные. Советуем сделать отдельное представление в Google Analytics, где будут события только с меткой prod (это можно сделать с помощью фильтра Представления).Там вы будете видеть только верно размеченные события. Результат. По мере устранения ошибок в разметке событий из инструкции, мы меняли значение параметра у этих событий в GTM с test на prod. Благодаря этому параметру мы включаем в отчеты только корректно размеченные события с меткой prod.
Как получить список доступных Google Analytics аккаунтов, ресурсов и представлений с их различными свойствами, настройками и параметрами в R
Воспользуйтесь одной из функций в пакете RGA:
- list_accounts для получения списка аккаунтов.Единственный обязательный аргумент функции — token, в который необходимо передать полученные ранее учетные данные, сохраненные в объект rga_auth.
- list_webproperties для списка доступных ресурсов с различными параметрами. Аналогично с предыдущим примером передайте в token полученные ранее учетные данные. С помощью аргумента accountId можно указать ID конкретного аккаунта, из которого вы планируете получить список доступных ресурсов. По умолчанию установлено значение «~all», что означает получить все доступные ресурсы.
- list_profiles для списка доступных представлений с их различными настройками и параметрами.Token, как и прежде, обязательный аргумент фукции. С помощью аргументов accountId и webPropertyId можно указать определенный аккаунт или ресурс, из которого вы планируете получить список представлений. По умолчанию оба аргумента равны «~all».
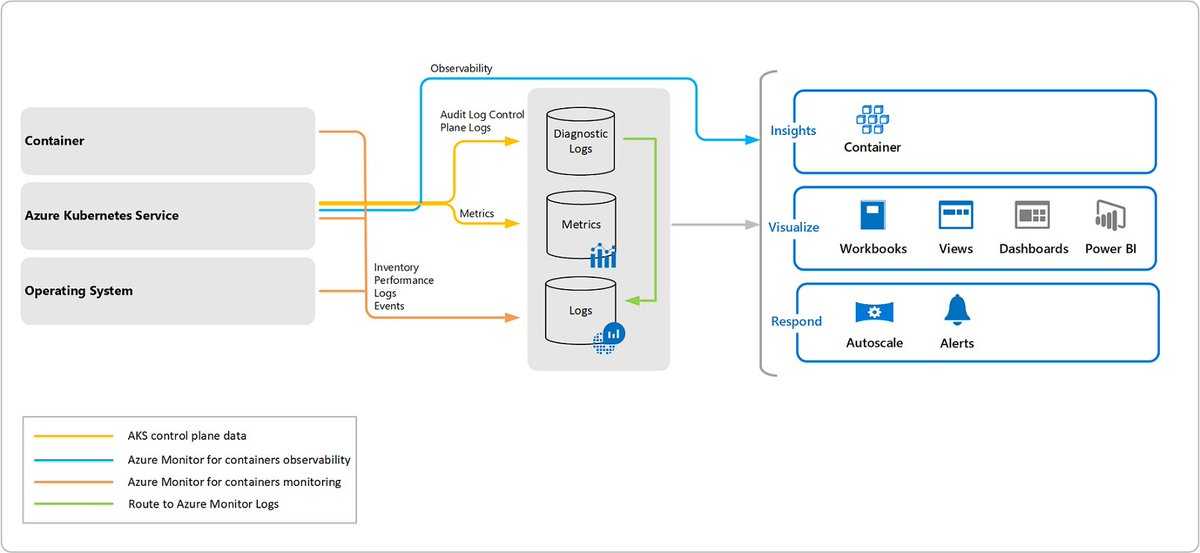
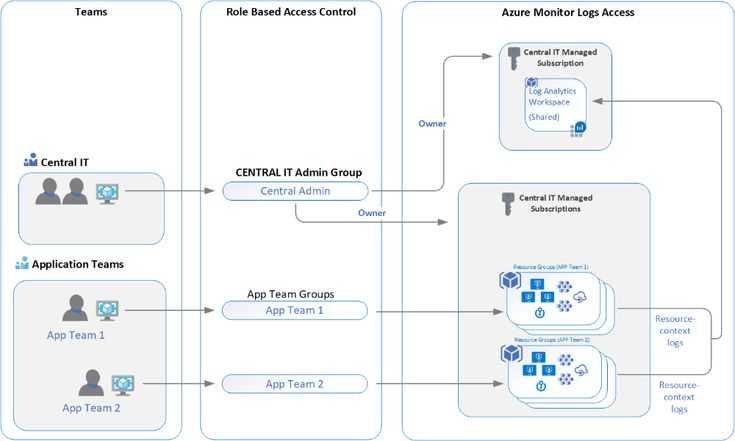
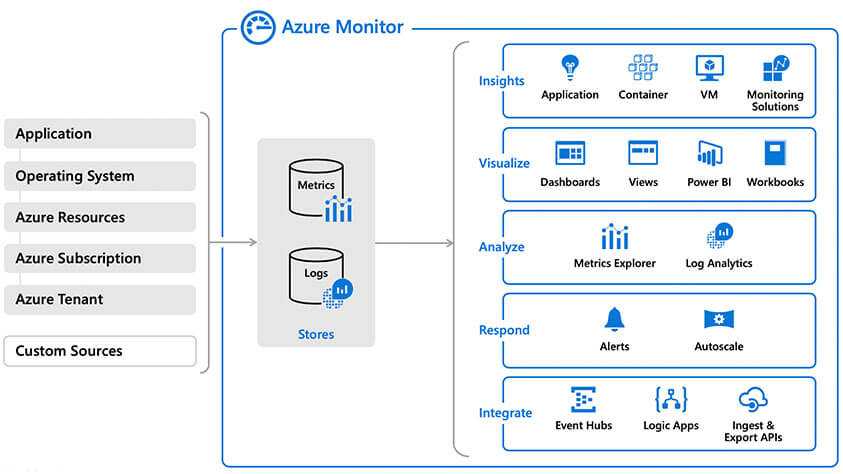
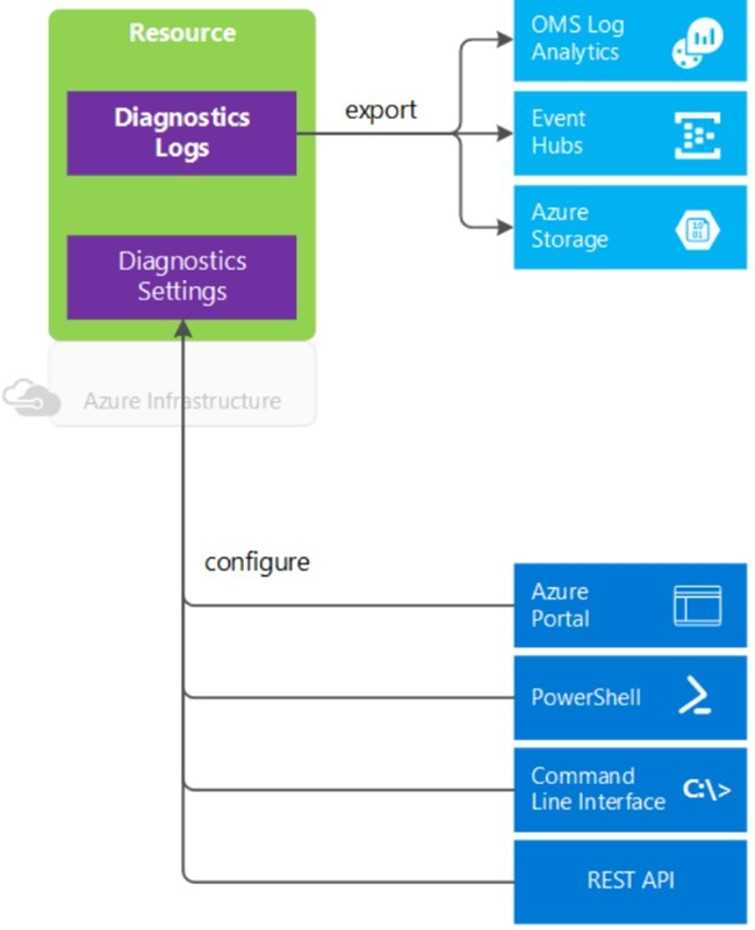
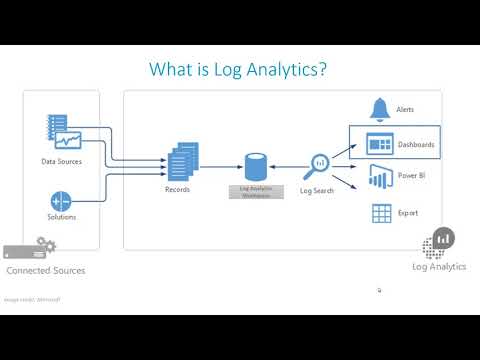
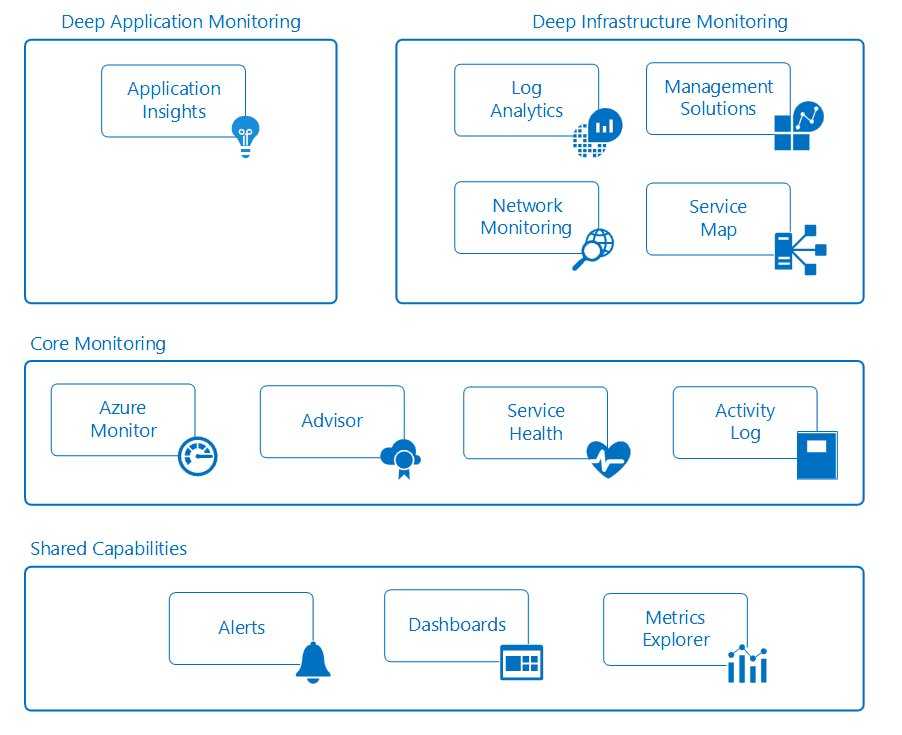
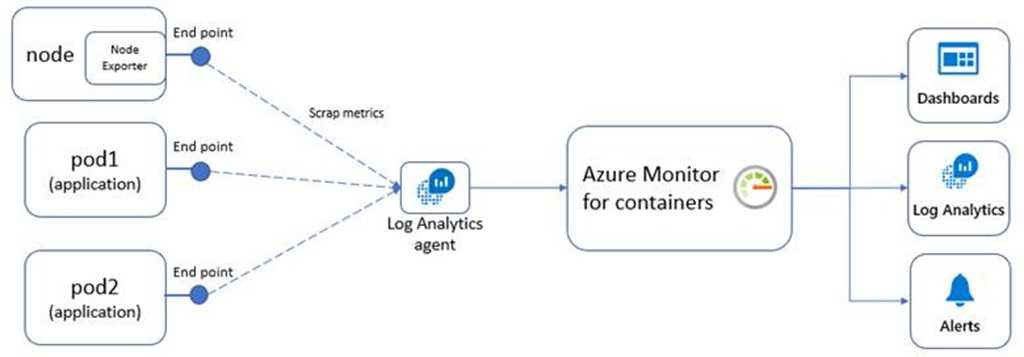
Связь с обозревателем данных Azure Data Explorer
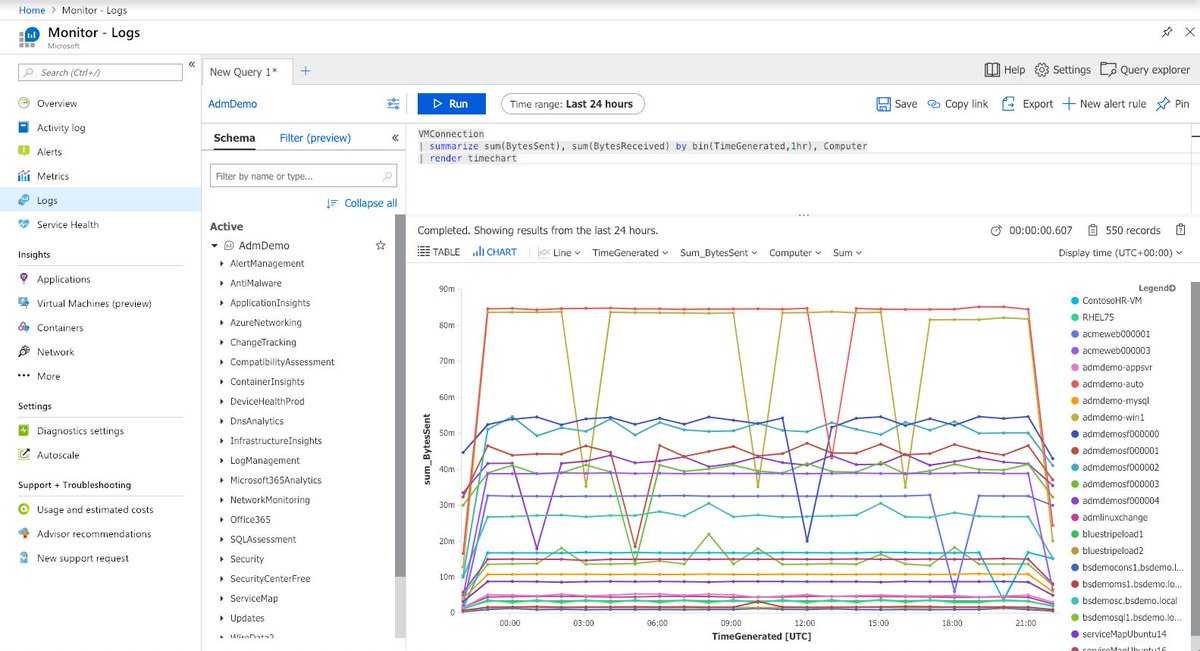
Если вы уже работали с веб-интерфейсом обозревателя данных Azure, Log Analytics также покажется вам знакомым. Это связано с тем, что данный инструмент создан на основе Azure Data Explorer и использует тот же язык запросов Kusto (KQL). В Log Analytics добавлены функции, специфичные для Azure Monitor, например фильтрация по диапазону времени и возможность создания правила генерации оповещений на основе запроса. Оба средства включают обозреватель, который позволяет просматривать структуру доступных таблиц, но пользовательский веб-интерфейс обозревателя данных Azure в основном работает с таблицами в базах данных Azure Data Explorer, тогда как Log Analytics работает с таблицами в рабочей области Log Analytics.
Tableau
Создает наборы данных, которыми можно делиться в режиме реального времени.
![]()
Tableau Public — это практически бесплатный инструмент визуализации с графиками, диаграммами, картами и многим другим. Вы легко сможете загрузить информацию в систему, а потом наблюдать за тем, как все обновляется. Для ускорения процесса можно работать одновременно с другими участниками проекта.

Бесплатное веб-приложение с простым интерфейсом.
![]()
Это приложение с открытым кодом, которое можно бесплатно скачать, изменить и настроить под себя. В нем можно делать векторные визуализации в форматах SVG или PNG.
Какое выбрать хранилище данных?
Центральный вопрос — куда, собственно, складывать данные. Основных критериев в случае Skyeng было три:
- скорость выполнения аналитических запросов;
- стоимость решения;
- сложность интеграции с системами аналитики и сервисами сбора данных.
Требования по скорости не позволили использовать традиционные строковые реляционные БД, а возможные интеграционные сложности заставили отказаться от всяких видов Hadoop as a Service и таких малораспространенных вариантов, как ClickHouse и Azure SQL Data Warehouse.
Крупные компании для подобных задач набирают команду data-инженеров и собирают пачку Hadoop-кластеров или выделяют бюджет на загрузку данных в Vertica, чтобы собирать там свое хранилище данных, но планка по деньгам сразу отсекла такие варианты.
Компании поменьше для таких задач используют Redshift или BigQuery; по большому счёту, между ними и пришлось выбирать. На мой взгляд, бессмысленно сравнивать эти сервисы по скорости — они оба достаточно быстрые, кроме разных пограничных случаев. У обоих есть развитая экосистема и интеграция с множеством сервисов.
Что касается цены, на первый взгляд может показаться, что BigQuery значительно дешевле. В минимальной конфигурации 1 кластер Redshift дает 160GB места и стоит ровно $180 в месяц, а BigQuery имеет гибкий ценник — всего лишь $0.02 за 1GB в месяц. Однако стоимость Redshift не зависит от количества и нагрузки аналитических запросов, в то время как в BigQuery запросы отдельно тарифицируются по $5 за 1TB обработанных данных — казалось бы, недорого.
Но давайте посмотрим на то, , и вспомним, что это колоночная база, и что для получения даже одного поля из одной строки нужно вытащить всю колонку. Возьмём какой-нибудь простейший вопрос: например, нам нужно посчитать по датам число пользователей, открывших конкретную страницу платформы Vimbox, это будет такой типовой запрос к BigQuery:
Здесь достаются данные из двух колонок: user_id типа integer и path типа string. Если в табличке, скажем, 100 млн. строк, то стоимость такого запроса составит несколько центов. Если у вас, например, 100 отчётов с подобными запросами, каждый из которых пересчитывается 2 раза в сутки, то ваш счет за месяц будет измеряться уже сотнями долларов.
Можно, конечно, использовать разные ухищрения, чтобы минимизировать число обрабатываемых данных. Например, можно класть всё в partitioned table и доставать во всех отчётах только данные за небольшой период. Но тогда получается, что вместо того, чтобы воодушевлять, BigQuery дестимулирует вас использовать эти ваши большие и даже не очень большие данные. Вместо того, чтобы стараться делать всевозможные запросы в поисках инсайтов, вы всё думаете, как бы их ограничить, — это грустная история.
В общем, я остановился на Redshift, держа в уме, что если есть какая-то более оптимальная конфигурация с BigQuery, то можно использовать и его.
Зачем это автоматизировать
Коллеги, с которыми я это обсуждала, сходятся на том, что современные сервисы аналитики предоставляют слишком много информации.
Например, в нашем случае нужно отслеживать ключевые показатели эффективности (KPI):
- из Google Analytics;
- четырёх социальных сетей, где мы совмещаем органический трафик и платное размещение;
- результатов опроса пользователей сайта;
- сервиса, который мониторит доступность и надёжность сайта в целом и эффективность поисковой оптимизации в частности;
- email-рассылок.
![]()
Это далеко не полный список, но мы решили начать с малого.
Все эти инструменты представляют данные разным образом, и извлекать их ручками (особенно из соцсетей) — так себе задачка. А если представить, что для разных групп в компании (буду дальше звать их стейкхолдерами) нужны разные KPI, и все хотят данные в лучшем случае за вчера, а не за прошлую неделю, то работа аналитика превращается в бесконечное создание графиков в Excel или одиноких дэшбордов в сервисах типа Tableau и рассылку презентаций коллегам.
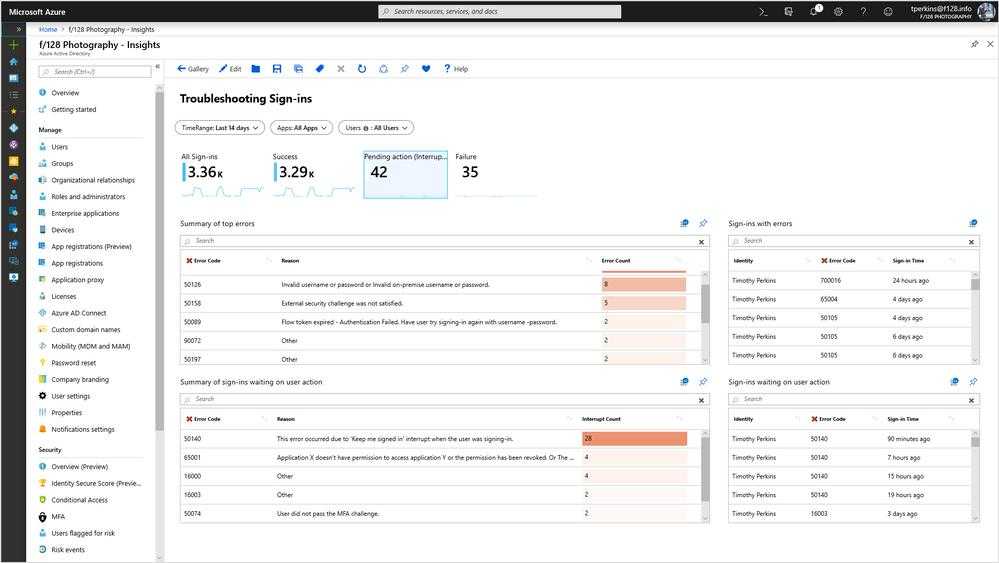
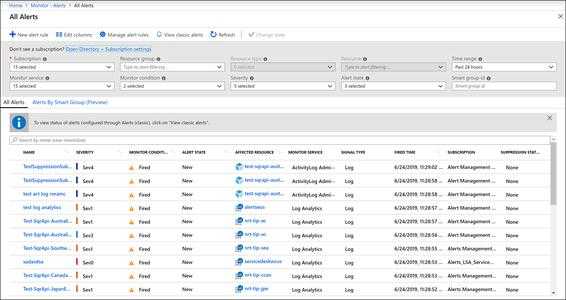
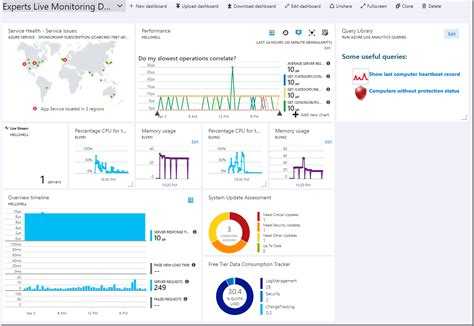
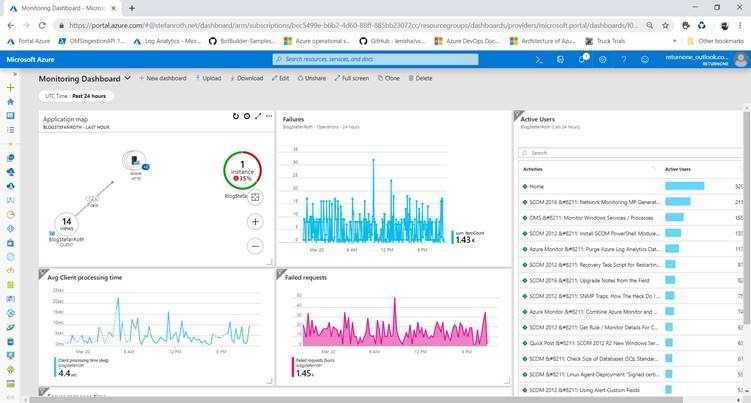
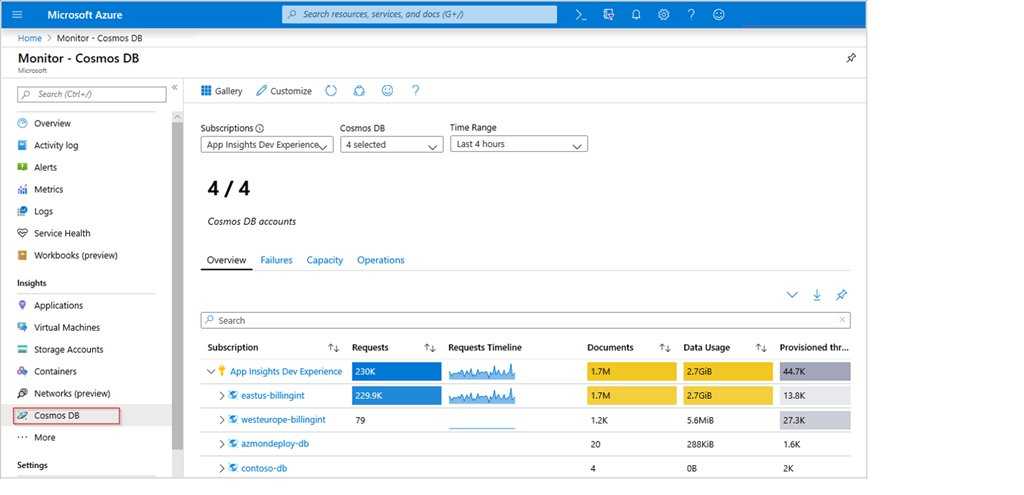
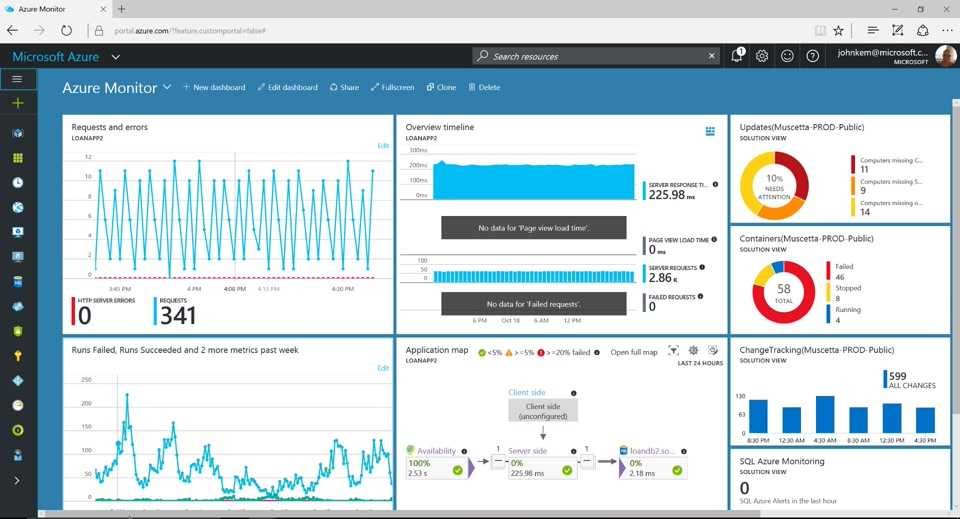
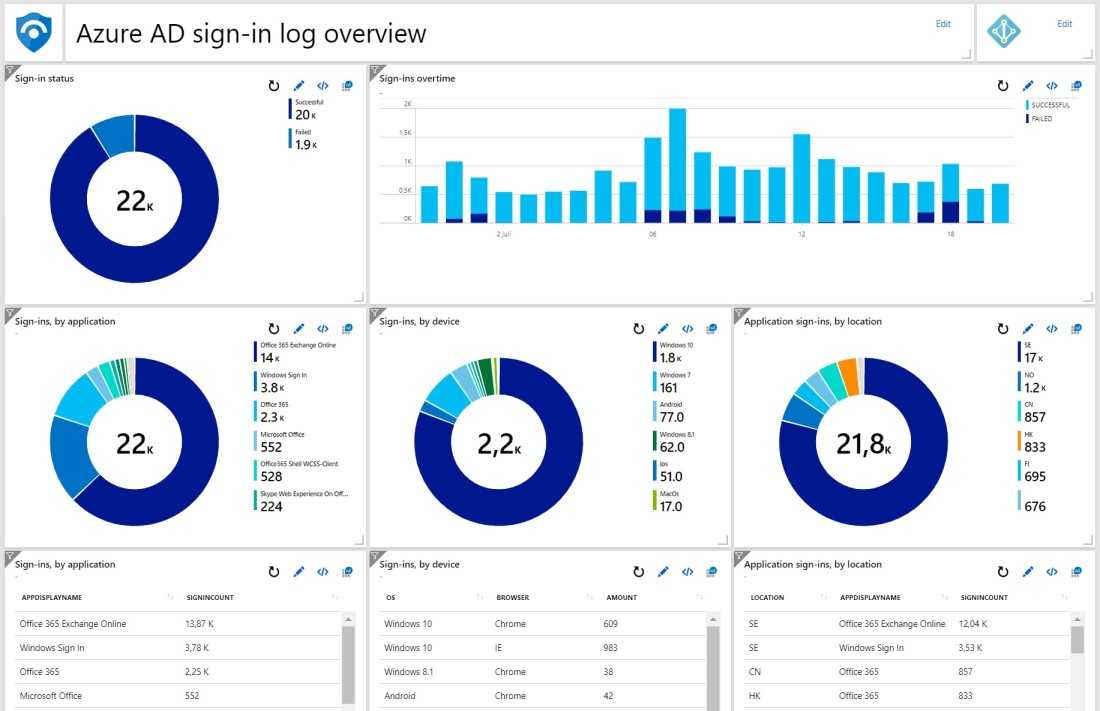
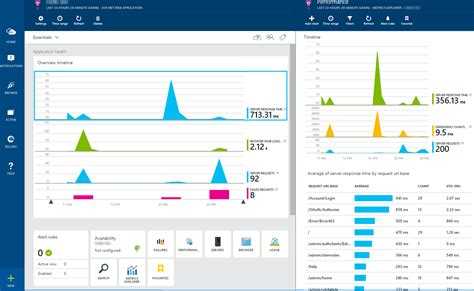
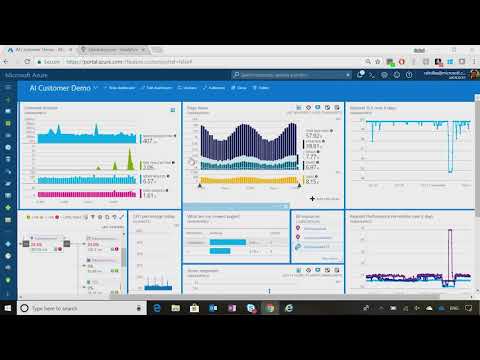
Анализировать результаты и планировать улучшения в этом случае уже некому. В крайнем случае это будет за вас делать Пушкин, а он, как мы знаем, не очень это любит.
В нашей ситуации было несколько групп стейкхолдеров:
- высший менеджмент, которому нужны данные верхнего уровня;
- менеджмент отдела коммуникаций, заинтересованный в общей картине;
- менеджмент бизнес-единиц, которым интересна отдача только их продуктов;
- локальные стейкхолдеры, управленцы, работающие на локальных рынках, желающие одновременно видеть общую картинку, следить за тем, что происходит в других странах, и, конечно, знать, что творится у них дома.
Развиваемся дальше
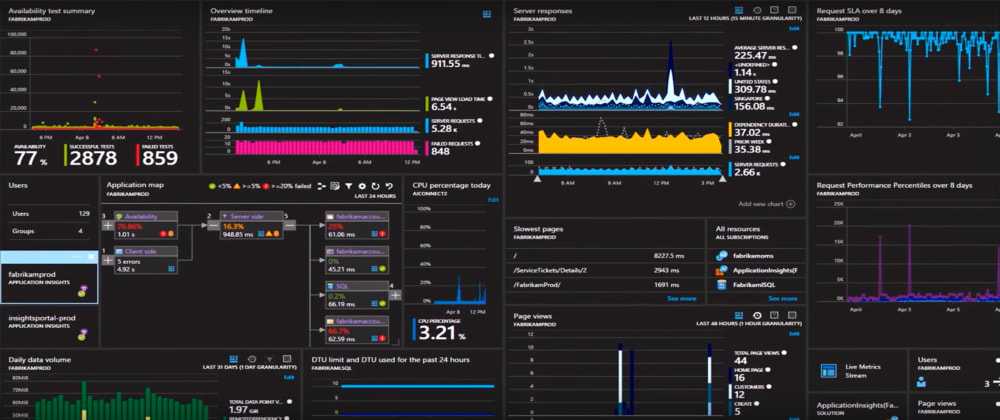
Сейчас интеграция находится на стадии версии v1.0, и мы планируем дальнейшие доработки. В частности, уже сейчас речь идет о том, чтобы расширить набор доступных аналитических возможностей, а также об интеграции в единую консоль управления (например, у Arenadata есть решение Cluster Manager (ADCM), которое позволяет управлять всеми компонентами ландшафта из единой консоли, рассматриваем это как один из вариантов).
Также на повестке дня остро стоит задача автоматизации настройки метаданных. Сейчас их нужно размечать в специальном интерфейсе — это довольно трудоемко. Хочется, чтобы система самостоятельно распознавала бы все необходимые параметры, получив путь к той или иной витрине.
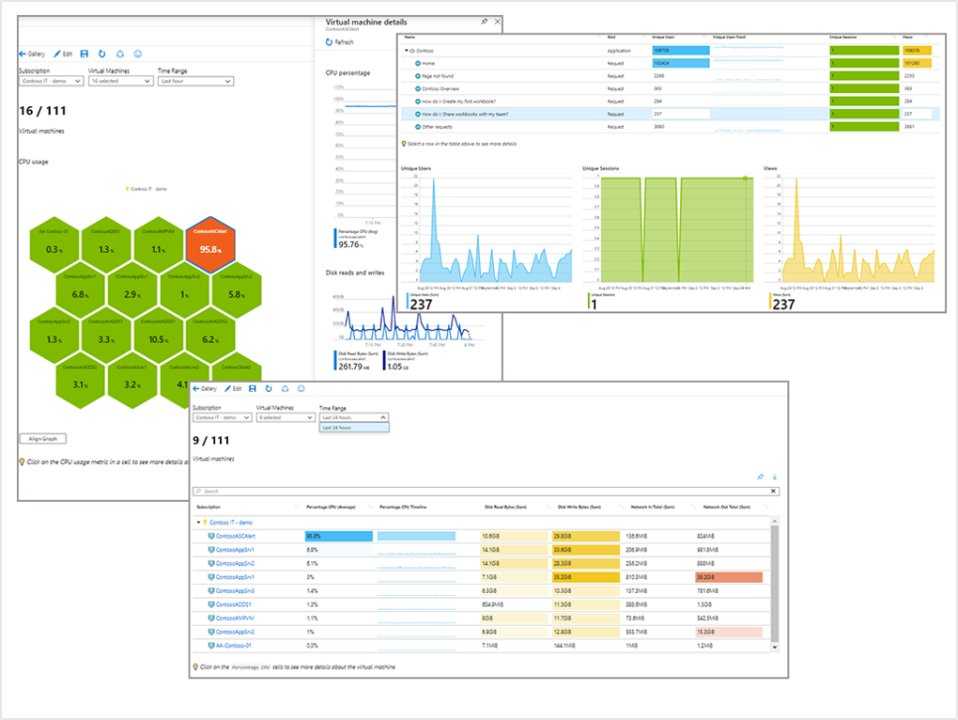
В целом, мы остались очень довольны и сотрудничеством с Arenadata, и той интеграцией с ClickHouse и ADQM, которая получилась. Теперь в аналитической платформе Visiology можно одновременно работать с источниками данных любого масштаба — от Small Data (ручной ввод, Excel) до Big Data (миллиардов или даже сотни миллиардов транзакций из распределенных хранилищ данных). А гибридный режим работы, который мы реализовали вместе с Arenadata, еще и позволяет сделать это с разумными затратами на оборудование.
Собираемые данные
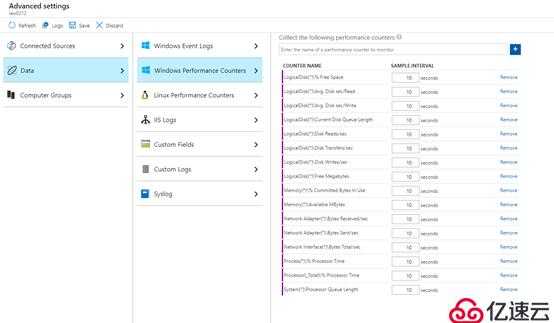
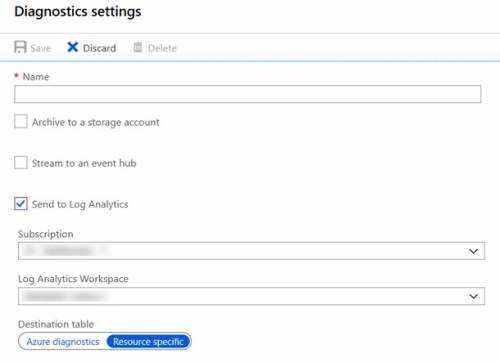
В этой таблице перечислены типы собираемых из всех подключенных агентов данных, которые вы можете настроить для рабочей области Log Analytics. Список аналитических сведений, и других решений, использующих агент Log Analytics для получения данных других типов, вы сможете найти в статье Что отслеживается Azure Monitor?.
| Источник данных | Описание |
|---|---|
| Журналы событий Windows | Информация, отправляемая системой ведения журналов событий Windows. |
| Syslog | Информация, отправляемая системой ведения журналов событий Linux. |
| Производительность | Числовые значения, представляющие собой оценки производительности разных элементов операционной системы и рабочих нагрузок. |
| Журналы IIS | Информация о потреблении для веб-сайтов на IIS, которые выполняются в гостевой ОС. |
| Пользовательские журналы | События из текстовых файлов на компьютерах Windows и Linux. |
Функциональное разнообразие
- быть разных типов:
линейный, столбчатый, древовидный и т. д.Картинки взяты отсюда. - быть адаптивными:
реагировать на изменение размера страницы.Картинка взята отсюда. - быть анимированными:
Например, допускать появление и удаление элементов.Пример взят здесь. - быть открытыми или закрытыми для кастомизации:
скажем, известную библиотеку D3 можно очень тонко настроить под свои нужды, в отличие от многих других библиотек. - быть стабильными или нет:
например, при загрузке данных значение какого-то параметра равного null/undefined может привести к полной неотрисовке графика. - быть кроссбраузерными или нет:
будет ли график работать в мобильной Opera? - поддерживать экспорт (сохранение) графика в картинку.
- поддерживать интеграцию с фреймворками:
сейчас трудно себе представить крупное приложение на чистом JS без Angular/React/тому подобное. - поддерживать сохранение/загрузку состояния:
например, сохранить состояние когда скрыта какая-нибудь серия точек на линейном графике.
фильтровать результаты запроса;
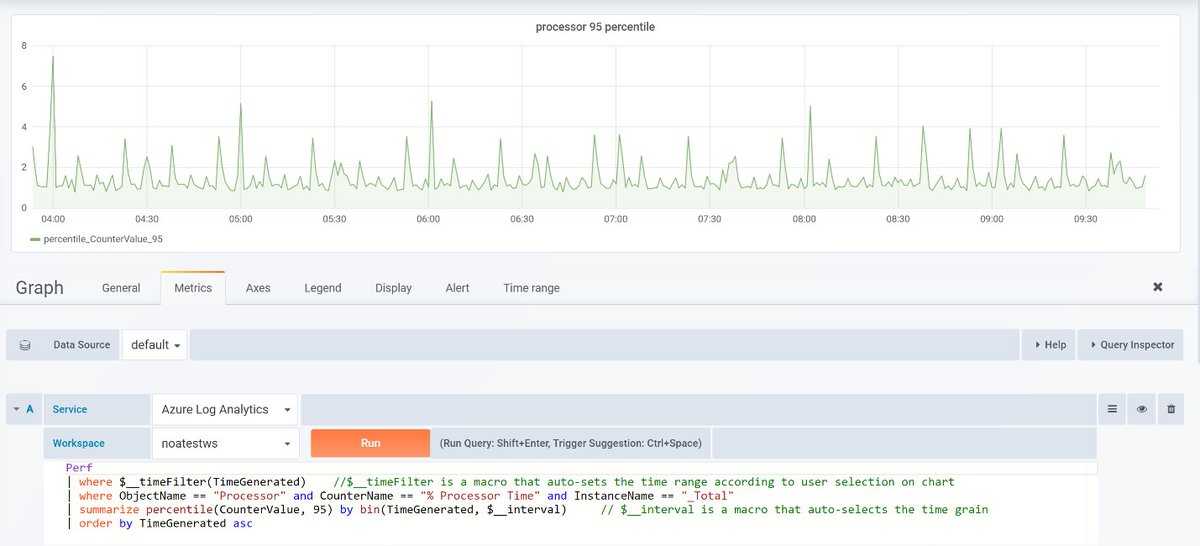
Давайте добавим фильтр к запросу, чтобы сократить количество возвращаемых записей. В области слева выберите вкладку Фильтр. На этой вкладке в результатах запроса отобразятся столбцы, которые можно использовать для фильтрации результатов. Верхние значения в этих столбцах отображаются с количеством записей, которые содержат это значение. В разделе ResultCode выберите 200, а затем — Применить и запустить.
Оператор where будет добавлен в запрос с выбранным значением. Теперь результаты содержат только записи с этим значением. Вы можете увидеть, что количество записей уменьшилось.
Диапазон времени
Все таблицы в рабочей области Log Analytics содержат столбец с именем TimeGenerated, который отображает время создания записи. Все запросы имеют диапазон времени, ограничивающий результаты записями со значением TimeGenerated в пределах этого диапазона. Диапазон времени можно задать либо в запросе, либо с помощью селектора в верхней части экрана.
По умолчанию запрос вернет записи, сформированные за последние 24 часа. Вы можете увидеть сообщение о том, что отображены не все результаты. Это связано с тем, что Log Analytics может возвращать не более 30 000 записей, а наш запрос вернул большее количество. Выберите раскрывающийся список Диапазон времени и измените значение на 12 ч. Выберите Запустить еще раз, чтобы вернуть результаты.
Несколько условий запросов
Давайте дополнительно сократим наши результаты, добавив еще одно условие фильтра. Запрос может включать любое количество фильтров, чтобы вы могли отобразить необходимый набор записей. Выберите Get Home/Index в разделе Имя и щелкните Применить и запустить.
Arenadata и Arenadata QuickMarts
Платформа данных Arenadata состоит из нескольких компонентов, построенных на базе открытых технологий, и используется многими российскими и зарубежными компаниями. В состав решения входит собственное MPP решение на базе Greenplum, дистрибутив Hadoop для хранения и обработки неструктурированных и слабоструктурированных данных, система централизованного управления ADCM (Сluster Management) на базе Ansible и другие полезные компоненты, в том числе Arenadata QuickMarts (ADQM).
СУБД ADQM — это колоночная СУБД от Arenadata, построенная на базе ClickHouse, аналитической СУБД, которую развивает Яндекс. Изначально ClickHouse создавалась для внутреннего проекта Яндекс.Метрика, но эта СУБД очень понравилась сообществу. В результате исходный код ClickHouse был переведен в OpenSource (лицензия Apache-2) и стал популярен по всему миру. На сегодняшний день насчитывается порядка 1000 инсталляций ClickHouse по всему миру, и только 1/3 из них в России. И хотя Яндекс остается основным контрибьютором развития СУБД, лицензия Apache-2 позволяет абсолютно свободно использовать продукт и вносить изменения в проект.
Современная колоночная СУБД использует аппаратную оптимизацию CPU (SSE). ClickHouse может очень быстро выполнять запросы за счет векторных оптимизаций и утилизации всего ресурса многоядерных CPU. На базе ClickHouse работают огромные кластера — сам Яндекс растягивает эту СУБД на несколько сотен серверов. Это гарантирует, что вместе с этим решением вы можете масштабироваться в достаточно больших объемах.
Но главная фича ClickHouse в нашем контексте — это эффективная работа с достаточно специфическими аналитическими запросами. Если витрины уже отстроены и вам нужно предоставить доступ пользователей к BI с минимальной латентностью, эта история как раз для ClickHouse. Эта СУБД прекрасно справляется с запросами без джойнов и соединений.
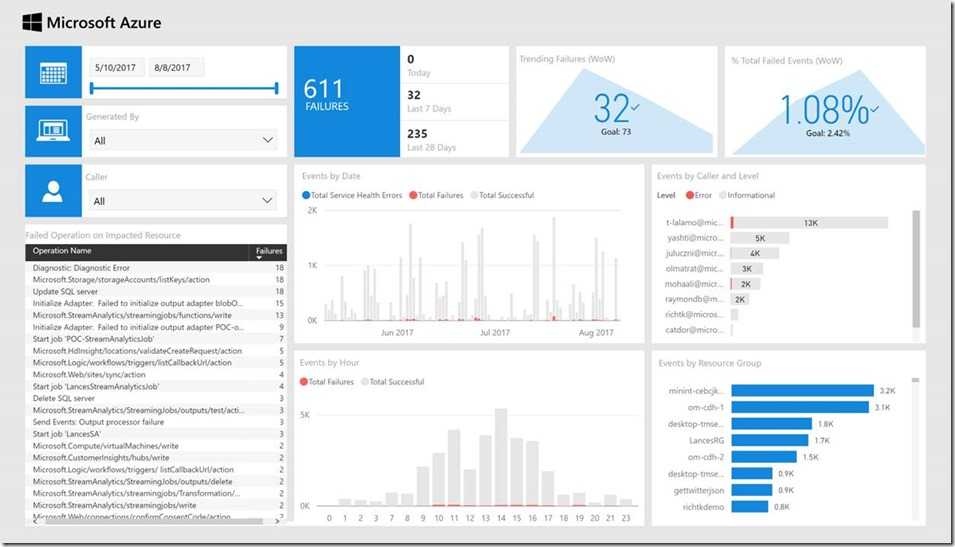
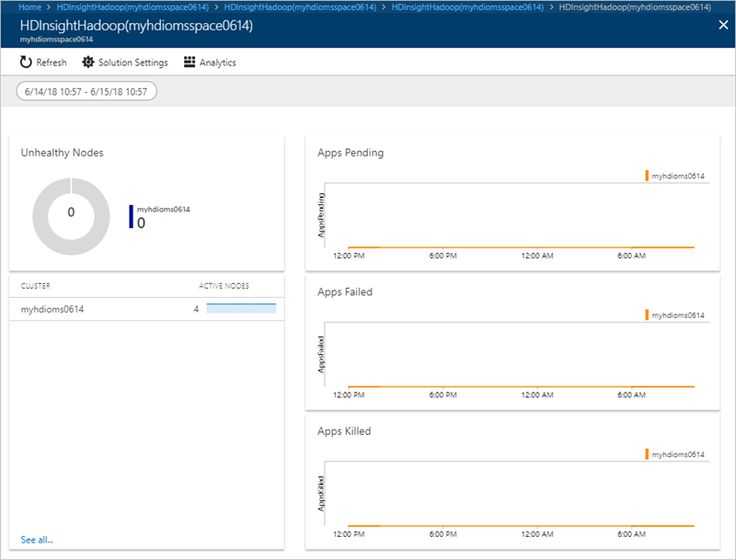
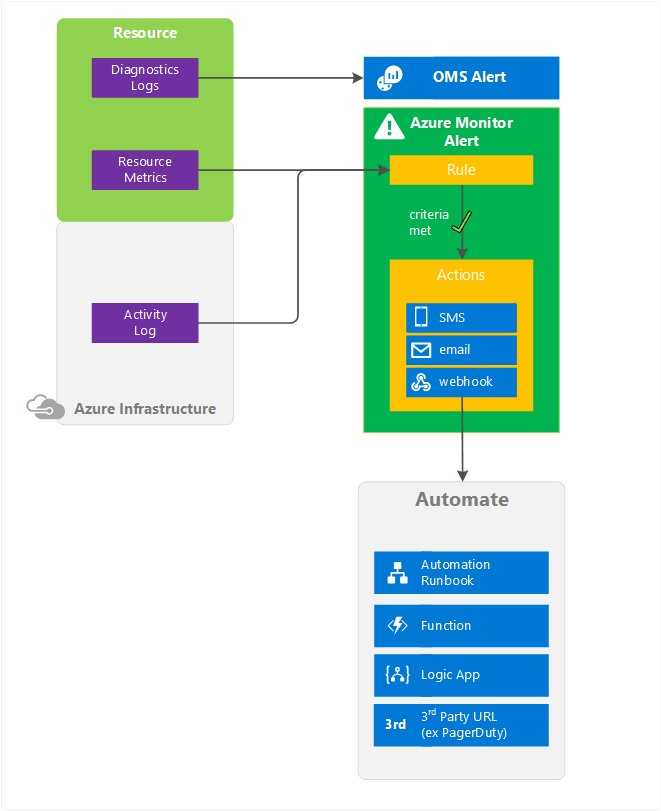
Во многих сравнениях ClickHouse дает серьезную фору даже классическим СУБД, например, той же Oracle Exadata. Результаты этих тестов можно найти на ресурсах Яндекса.
Какой выбрать сервис загрузки данных из баз?
Помимо сбора событий непосредственно из продуктов, нам нужно ещё и выгружать данные из их баз, а у Skyeng это целый зоопарк — разные инстансы разных версий MySQL и PostgreSQL, как облачные, так и на собственных серверах. Существуют решения, которые делают и то, и другое: например, Treasure Data и Alooma; однако стоимость у них крайне непрозрачна и в выделенный бюджет однозначно не вписывается (в год ~$30K за Alooma или $60K за Treasure Data при условии ежемесячной отправки 100 млн событий из приложений и 100 млн строк из баз данных).
Ещё раз уточню, что варианты писать своё ETL-решение, даже на основе существующих фреймворков типа Luigi или Airflow, и программировать пайплайны были отброшены сразу же, так как требуют как минимум ещё одной пары рук программиста и соответствующего увеличения фонда оплаты труда.
Из автоматических сервисов мне были известны только FlyData, Fivetran, Xplenty и Stitch, и я выбрал просто самый дешёвый из них — Stitch даёт бесплатный триал на месяц, в течение которого можно выгрузить все исторические данные и настроить инкрементальную репликацию новых данных (до 100 млн строк в месяц за $500).
В отличие от Xplenty, который по сути является полноценным ETL-сервисом с поддержкой различных трансформаций данных, Stitch имеет довольно примитивный интерфейс и позволяет просто отметить галочками, какие таблицы и какие поля из них (или все) вы хотите реплицировать, с какой периодичностью и каким способом.
В Stitch поддерживается полная перезапись и инкрементальная репликация по ключу, которым может быть, например, первичный ключ, если строки в исходную таблицу только добавляются, но не изменяются, либо, например, updated_at, если это поле хранит дату последнего изменения строки. При необходимости трансформации данных до перенесения в хранилище нужно прямо в исходной базе создать view с нужными данными и реплицировать этот view аналогичным образом.
Должен сказать, что такое простое решение оказывается достаточным в большинстве случаев.
Stitch поддерживает различные хранилища, сам осуществляет преобразования типов данных в зависимости от хранилища (например, json и enum переводит в varchar в случае Redshift), а также следит за структурой исходной базы и изменениями в таблицах — новые колонки подцепляются автоматически. Ещё у них толковая служба поддержки, которая много раз помогала мне решать самые разные вопросы прямо в окошке чата.
По деньгам всё же это первый кандидат на замену в выбранной архитектуре, потому что при росте числа реплицируемых таблиц очень быстро станет выгодным просто завести отдельного ETL-разработчика.
Что такое EDA или визуализация данных для Data Science
В отличие от инфографики, которая ближе к дизайну, чем к Data Science, визуализация данных не содержит декоративных элементов, а отражает большие объёмы информации с учетом возможных взаимосвязей . Но в Data Science визуализация данных используется не только для наглядного представления результатов в виде понятных графиков. Это скорее метод быстрого прототипирования, когда с помощью множества визуальных представлений одних и тех же данных аналитик или Data Scientist пытается обнаружить скрытые взаимосвязи и зависимости . Этот подход называется разведочный анализ данных (Exploratory Data analysis, EDA) и применяется для решения следующих задач :
- максимальное погружение в данные;
- выявление основных структур;
- выбор наиболее важных переменных;
- обнаружение отклонений и аномалий;
- проверка основных гипотез;
- разработка начальных моделей.
Можно сказать, что EDA – часть процесса подготовки данных к ML-моделированию, когда после этапов выборки и очистки датасета выполняется генерация признаков (рис. 1.).
Рис. 1. Место EDA в Data Science
Кроме того, EDA позволяет Data Scientist’у убедиться в корректной интерпретации результатов и их применимости к желаемому бизнес-контексту. А бизнес-пользователи могут оперативно проверить правильность своих предположений, в т.ч. то, что они задают правильные вопросы. Таким образом, EDA играет роль средства валидации – оценки того, насколько данные соответствуют бизнес-целям
Это особенно важно при работе с Big Data, когда датасет собирается из множества различных источников с разными уровнями точности и детализации. На практике EDA даже приводит к интересным бизнес-инсайтам
Например, определение четкой зависимости суммы чека от времени суток, корреляция числа посетителей с погодными условиями и т.д.
Математическую основу EDA составляют статистика и теория вероятностей, в частности, вероятностные распределения переменных, корреляционные матрицы, факторный анализ, дискриминантный анализ, многомерное шкалирование. В качестве практических инструментов для разведочного анализа используются специализированные математические программы (SAS, Matlab, KNIME, Weka, Orange), системы типа RStudio, оригинальные скрипты на Python и даже встроенные формулы табличных редакторов, таких как Excel и Google Sheets . Подробнее инструменты EDA и визуализации данных рассмотрены далее.

Основные способы визуализации
Перечисляем самые распространенные способы визуализации, с примерами.
Графики
Наверное, самый привычный для нас вид визуализации данных. Именно графики мы видим в учебниках в школе, с ними же первым делом знакомимся, когда начинаем осваивать Excel.
Графики строятся по осям X и Y и показывают зависимость данных друг от друга. Они, в свою очередь, делятся еще на несколько подвидов — подробнее о каждом по ссылкам ниже.
Свечной график
График плотности
График баров (OHLC)
Линейный график
График Каги
График «крестики-нолики»
Скрипичный график
Спиральный график
Потоковый график
Диаграммы
Еще один распространенный способ визуализации. Показывают соотношения набора данных или связи внутри набора данных. В основном строятся вокруг осей, но не всегда.Также их можно построить по секторам или полярной системе координат.
Сегодня насчитывается более 60 различных диаграмм. И это еще не конец — люди продолжают придумывать новые типы для визуализации сложных и необычных данных.
Дуговая диаграмма
Диаграмма с областями
Столбиковая диаграмма
Диаграмма размаха («ящик с усами»)
Пузырьковая диаграмма
Пулевая диаграмма
Хордовая диаграмма
Кольцевая диаграмма
Гистограмма
Диаграмма Маримекко
Столбиковая диаграмма с группировкой
Сетевая диаграмма
Диаграмма «роза найтингейл»
Неленточная хордовая диаграмма
Диаграмма с параллельными координатами
Пиктографическая диаграмма
Круговая диаграмма
Диаграмма с пропорциональными областями
Радиальная диаграмма
Радиальная полосчатая диаграмма
Радиальная столбчатая диаграмма
Диаграмма рассеяния
Диаграмма диапазонов
Облако слов
Накопительная диаграмма с областями
Диаграмма «стебель-листья»
Диаграмма «Солнечные лучи»
Диаграмма Венна
Заключение
Отчёт в Google Data Studio пригодится как специалистам по маркетингу, так и их клиентам. Маркетологи смогут в один клик узнать информацию по своим рекламным кампаниям и оперативно отреагировать на изменения в эффективности. Или, наоборот, построить данные на большом промежутке времени и понять, что статистика меняется в пределах нормы.
Клиенты же смогут самостоятельно в любое время получать из отчёта всю необходимую им информацию в удобном виде и меньше отвлекать маркетолога.
Источник фото на тизере: William Felker on Unsplash
Рекомендуем:
- 4 сайта, 18 маркетинговых каналов: автоматизируем аналитику с помощью Power BI
- Кейс: нужна ли сквозная аналитика небольшому региональному бизнесу
- Как мы автоматизировали бизнес-процессы и избавились от рутины: опыт агропромышленного холдинга
- Какие 20% усилий приносят 80% прибыли в омниканальном маркетинге
- Google Ads: Discovery Ads vs. Стандартные KMC