
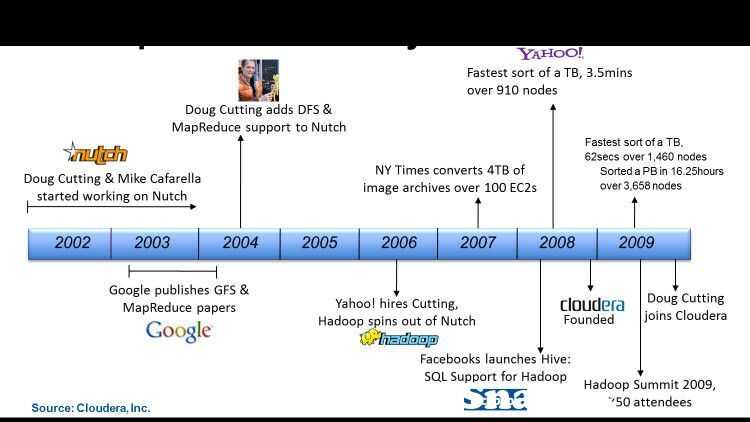
Коллективная работа
Для создания документа в «Яндекс.документах» аккаунт в «Яндексе» потребуется обязательно. Затем все будет зависеть от его автора – он сможет работать над ним в одиночку, или же ему всегда доступна одна из основных особенностей сервиса – возможность открыть к нему доступ коллегам (и не только им).
Для этого владельцу документа нужно сгенерировать ссылку на документ и отправить ее требуемым адресатам по почте, в мессенджер или любым другим способом. Получатели смогут подключиться к работе над таблицей, презентацией или docx-файлом без необходимости регистрации или авторизации в экосистеме «Яндекса».
Окно генерации ссылки на документ
Каждый из подключенных пользователей сможет вносить свои правки в документ, которые сразу станут доступны другим участникам виртуального «коворкинга». В сервисе по умолчанию есть защита от случайного удаления фрагмента документа – она реализована при помощи истории изменений, и для отмены удаления достаточно будет выбрать один из предыдущих вариантов этого документа.
Базовые принципы
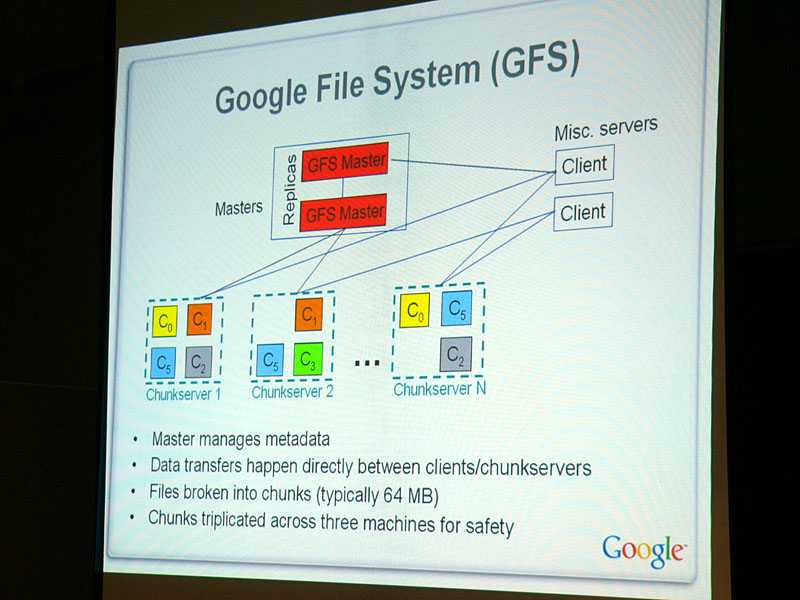
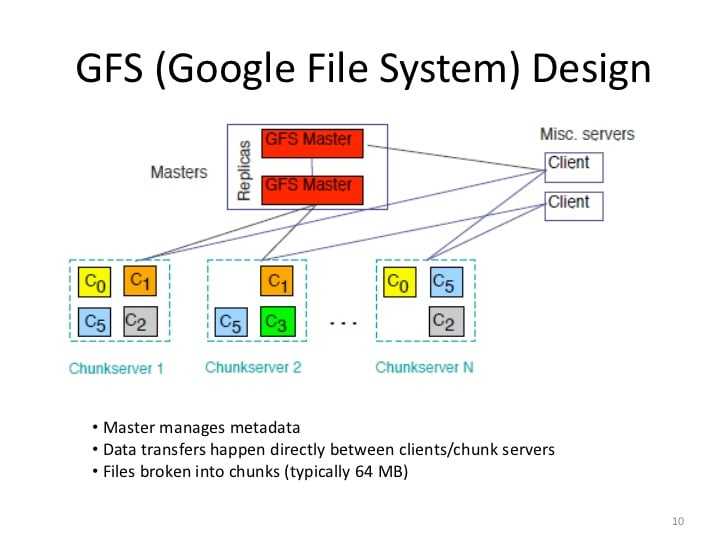
Основными принципами, заложенными инженерами Google в GFS являются:
- Аппаратные неисправности в кластерных системах нужно рассматривать как норму, а не как исключение.
- Данные уже имеют огромный размер и их объем будет только расти. Система ввода-ввода должна быть спроектирована с расчетом на размер данных, которыми она будет оперировать.
- Файлы изменяются путем добавления новых данных в конец файла, а не путем переписывания существующих данных. Запись в произвольные места, как не непоследовательное чтение данных из файла гипернеэффективны. Эффективно использование подхода «write once, read many».
- Дизайн распределенной ФС, не должен полагаться на дизайн приложений, его использующих. Таким образом файловая система должна знать минимальное количество сведений о клиентах и характере операций над данными, которые эти клиенты осуществляют.
Спектакль
Исходя из результатов тестирования, при использовании с относительно небольшим количеством серверов (15) файловая система достигает производительности чтения, сопоставимой с производительностью одного диска (80–100 МБ / с), но имеет пониженную производительность записи (30 МБ / с. ) и относительно медленно (5 МБ / с) добавляет данные в существующие файлы. Авторы не приводят результатов по случайному времени поиска. Поскольку главный узел не участвует непосредственно в чтении данных (данные передаются с сервера фрагментов непосредственно клиенту чтения), скорость чтения значительно увеличивается с увеличением количества серверов фрагментов, достигая 583 МБ / с для 342 узлов. Агрегирование нескольких серверов также обеспечивает большую емкость, хотя она несколько уменьшается за счет хранения данных в трех независимых местах (для обеспечения избыточности).
Зачем понадобился GFS2? Ограничения GFS
Одним из таких принципиальных ограничений связки «GFS + Google MapReduce », как и аналогичной связки «HDFS + Hadoop MapReduce (Classic) » (до появления ), была ориентированность исключительно на пакетную обработку данных. В то время как все больше сервисов Google – социальные сервисы, облачное хранилище, картографические сервисы – требовали значительно меньших задержек, чем те, которые свойственны пакетной обработке данных.
Таким образом, в Google столкнулись с необходимостью поддержки near-real-time ответов для некоторых типов запросов.
Кроме того, в GFS chunk имеет размер 64 Мб (хотя размер chunk конфигурируемый), что, в общем случае, не подходит для сервисов Gmail, Google Docs, Google Cloud Storage — бОльшая часть места выделенного под chunk остается незанятой.
Уменьшение размера chunk автоматически привело бы к увеличению таблицы метаданных, в которой хранится file-to-chunk маппинг. А так как:
- доступ, поддержка актуальности и репликация метаданных – это зона ответственности Master сервера;
- в GFS, как и в HDFS, метаданные полностью загружаются в оперативную память сервера,
то очевидно, что один Master на GFS-кластер — потенциально узкое место в распределенной файловой системе с большим числом chunk’ов.
Кроме того, современные сервисы являются географически распределенными. Геораспределенность позволяет как остаться сервису доступным во время форс-мажоров, так и сокращает время доставки контента до пользователя, который его запрашивает. Но архитектура GFS, описанная в , как классическая «Master-Slave»-архитектура, не предполагает реализацию географической распределенности (во всяком случае без существенных издержек).
Широкий спектр сервисов
«Яндекс.документы» с момента запуска входит в состав набора веб-сервисов «Яндекс.360». Представители компании объяснили это тем, в настоящее время «в нем есть все, что нужно для работы: не только сервисы для делового общения и хранения файлов, но и для работы с документами».
Что дает интеграция ИТ-систем и московских судов
ИТ в госсекторе
![]()
Помимо «Документов», в «Яндексе 360» есть «Почта» (для работы с электронной почтой), «Диск» (облачное хранилище файлов), «Телемост» (сервис проведения видеоконференций», а также «Календарь», «Заметки» и «Мессенджер». Каждым из перечисленных сервисов можно пользоваться бесплатно.
Ссылки
- Распределенная файловая система GFS, 29 октября 2009
- GFS: Evolution on Fast-forward, by Marshall Kirk McKusick, Sean Quinlan, August 1, 2009
| Google Inc. | |
|---|---|
|
|
|
|
| Коммуникации |
|
| ПО |
|
| Платформы |
|
| Инструментыразработки |
|
| Публикация |
|
| Поиск (PageRank,руководства) |
|
| Тематические проекты |
|
| Закрытые проекты |
|
| См. также |
|
| Файловые системы (список, сравнение) | |||||||
|---|---|---|---|---|---|---|---|
| Дисковые |
|
||||||
| Распределённые(сетевые) |
|
||||||
| Специальные |
|
Что умеет сервис
На момент запуска сервис «Яндекс.документы» работал только с текстовыми документами, таблицами и презентациями. О возможности появления в его составе дополнительных инструментов для совместной работы, например, над диаграммами (как в Google Drawings) информации в настоящее время нет. «В дальнейшем мы будем развивать функциональность сервиса “Документы” и рассказывать об этом дополнительно», – сообщили CNews представители «Яндекса».
Каталог презентаций
«Яндекс.документы» поддерживает наиболее распространенные форматы перечисленных типов документов – docx, xlsx и pptx, внедренные корпорацией Microsoft с релизом Office 2007. Новый сервис «Яндекса» работает только с ними, но в то же время у него есть инструментарий для конвертирования документов, созданных в старых версиях форматов (doc, xls и ppt) в более новые. Работать можно как с полностью новыми документами, так и созданными в офлайн-пакетах офисных программ или конкурирующих сервисов. Для этого реализована функция загрузки файлов из памяти устройства – компьютера или мобильного гаджета.
Веб-версия «Яндекс.документов» на экране смартфона
Для более удобной навигации по файлам в верхней части перечня отображаются те, которые открывались последними. При необходимости все документы можно отсортировать по названию или размеру, словом, в этом плане «Яндекс.документы» повторяет «Проводник» — файловый менеджер в ОС Windows. Дополнительно предусмотрена возможность закрепления любого документа из имеющихся, чтобы работающие над ним пользователи могли быстро открыть его.
Battle-tested to deliver massive scale
So, there you have it—Colossus is the secret scaling superpower behind Google’s storage infrastructure. Colossus not only handles the storage needs of Google Cloud services, but also provides the storage capabilities of Google’s internal storage needs, helping to deliver content to the billions of people using Search, Maps, YouTube, and more every single day. When you build your business on Google Cloud you get access to the same super-charged infrastructure that keeps Google running. We’ll keep making our infrastructure better, so you don’t have to.
To learn more about Google Cloud’s storage architecture, check out the Next ‘20 session from which this post was developed, “A peek at the Google Storage infrastructure behind the VM .” And check out the cloud storage website to learn more about all our storage offerings.

![Файловая система google содержание а также дизайн [ править ]](https://sariola.ru/wp-content/uploads/6/4/8/648e2cfebcb3c59de3b477f506cd3694.jpeg)

Российский ответ Google Docs
Российский интернет-гигант «Яндекс» запустил веб-сервис для совместной работы над документами, электронными таблицами и презентациями. Как сообщили CNews представители компании, проект получил название «Документы».
«Яндекс.документы» позволяет работать с перечисленными типами файлов даже при полном отсутствии на ПК или мобильном устройстве предустановленного офисного пакета. Кроме того, совместная работа в этом сервисе будет доступна даже тем, у кого нет аккаунта в «Яндексе».
На момент публикации материала сервис был доступен не всем пользователям «Яндекса» и существовал исключительно в веб-версии, подключиться к которой можно было через браузер на компьютере, планшете или смартфоне. На запрос CNews о сроках открытия доступа к «Документам» всем пользователям представители «Яндекса» сообщили: «В ближайшее время переходить в “Документы” пользователи смогут из интерфейса “Яндекс.почты”, а затем и из других сервисов, входящих в набор для работы “Яндекс 360”». Также они прокомментировали ситуацию с отсутствием у сервиса фирменного приложения: «Уже сейчас можно редактировать документы также в мобильной версии в популярных браузерах. В дальнейшем сервис “Документы” будет доступен и в мобильных приложениях “Почты”, “Диска”, “Телемоста”, входящих в набор сервисов для работы “Яндекс 360”».
«Яндекс.документы»
Дополнительных платных функций, как рассказали CNews представители «Яндекса», в новом сервисе не будет. «”Документы” – это бесплатный сервис. Если пользователю для работы потребуется, например, больше места на “Диске” или красивый домен для почтового адреса, то эти и другие дополнительные возможности можно получить по подписке на набор сервисов для работы “Яндекс 360”», – отметили они.
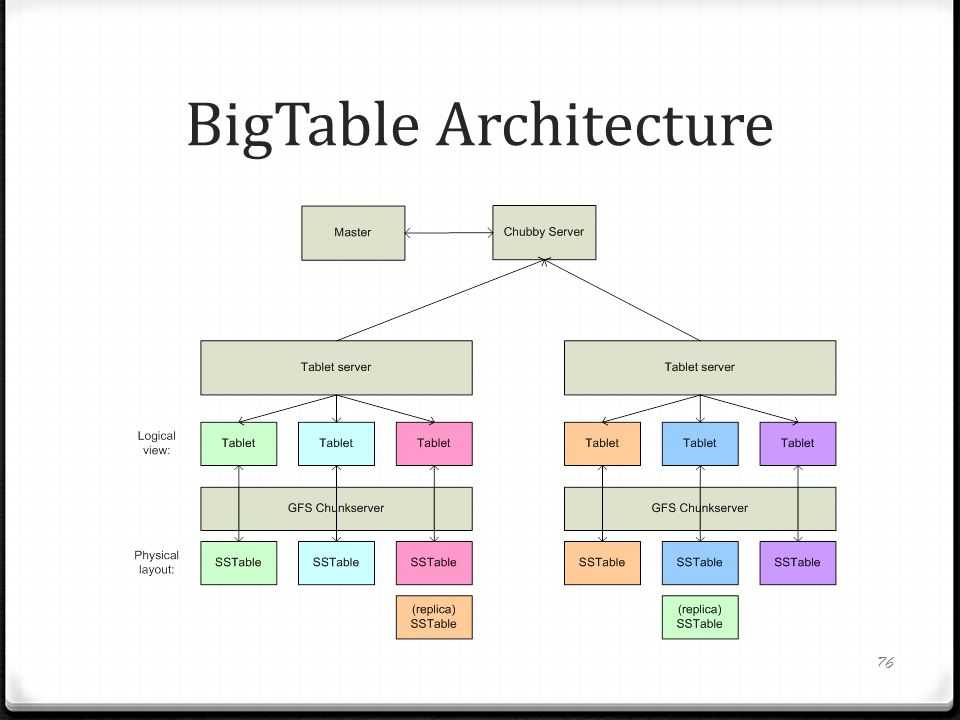
Архитектура
(Disclaimer: я не нашел ни одного достоверного источника, в полной мере описывающего архитектуру Colossus, поэтому в описании архитектуры имеются как пробелы, так и предположения.)
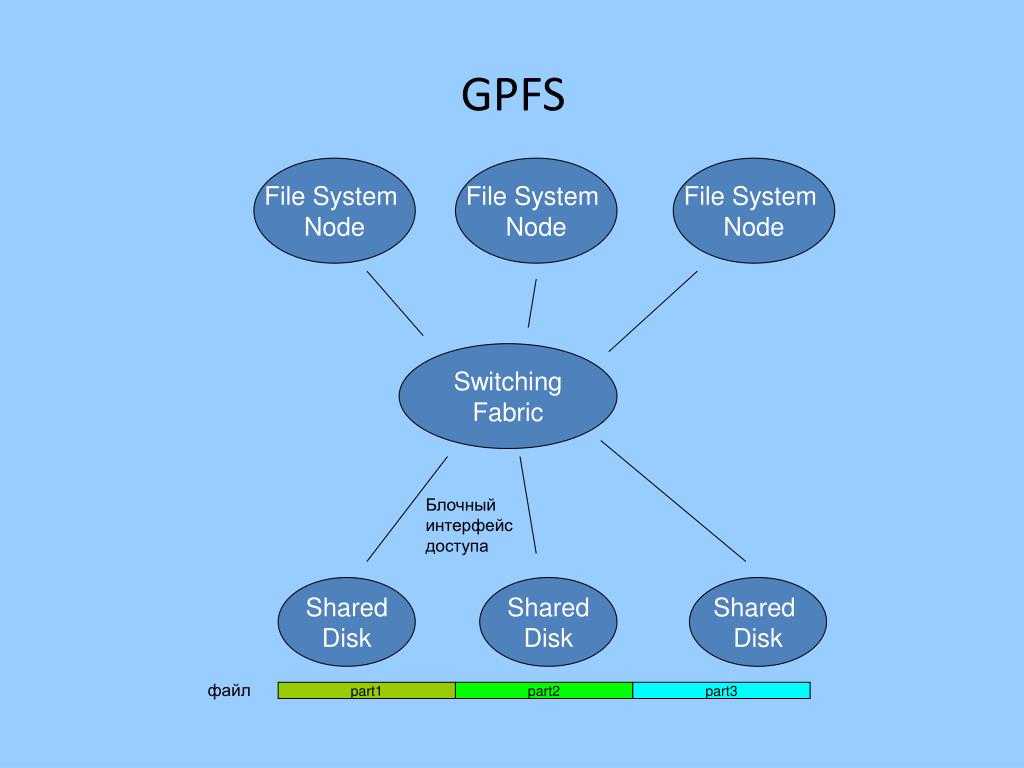
Colossus был призван решить проблемы GFS, описанные выше. Так размер chunk’а был уменьшен до 1 Мб (по умолчанию), хотя по-прежнему остался конфигурируемым. Возрастающие требования Master-серверов к объему оперативной памяти, необходимой для поддержания таблицы метаданных, были удовлетворены новой «multi cell»-ориентированной архитектурой Colossus.
Так в Colossus есть пул Master-серверов и пул chunk-серверов, разделенных на логические ячейки. Отношение ячейки Master-серверов (до 8 Master-серверов в ячейке) к ячейкам Сhunk-серверов является один ко многим, то есть одна ячейка Master-серверов обслуживает одну и более ячейку Сhunk-серверов.
Внутри ЦОД группа ячейка Master-серверов и управляемые ей ячейки Chunk-серверов образуют некоторую автономную — не зависящую от других групп такого типа – файловую систему (далее для краткости SCI, Stand-alone Colossus Instance). Такие SCI расположены в нескольких ЦОД Google и взаимодействуют друг с другом по средством специально разработанного протокола.



Т.к. в открытом доступе нет подробного описанного инженерами Google внутреннего устройства Colossus, то не ясно, как решается проблема конфликтов, как между SCI, так и внутри ячейки Master-серверов.
Один из традиционных способов решения конфликтов между равнозначными узлами – это кворум серверов. Но если в кворуме четное количество участников, то не исключены ситуации, когда кворум ни к чему и не придет – половина «за», половина «против». А так как в информации о Colossus очень часто звучит, что в ячейке Master-серверов может находится до 8 узлов, то решение конфликтов с помощью кворума ставится под сомнение.
Также совершенно не ясно, каким образом одна SCI знает, какими данными оперирует другая SCI. Если предположить, что такими званиями SCI и не обладает, то это означает, что этими знаниями должен обладать:
- либо клиент (что еще менее вероятно);
- либо (условно) Supermaster (который опять же является единичной точкой отказа);
- либо это информация (по сути critical state) должна находится в разделяемом всеми SCI хранилище. Тут ожидаемо возникают проблемы блокировок, транзакций, репликации. С последними успешно справляется PaxosDB, либо хранилище реализующее алгоритм Paxos (или аналогичный).
В общем Colossus в целом пока скорее «черный ящик», чем «ясная архитектура» построения геораспределенных файловых систем, оперирующих петабайтами данных.
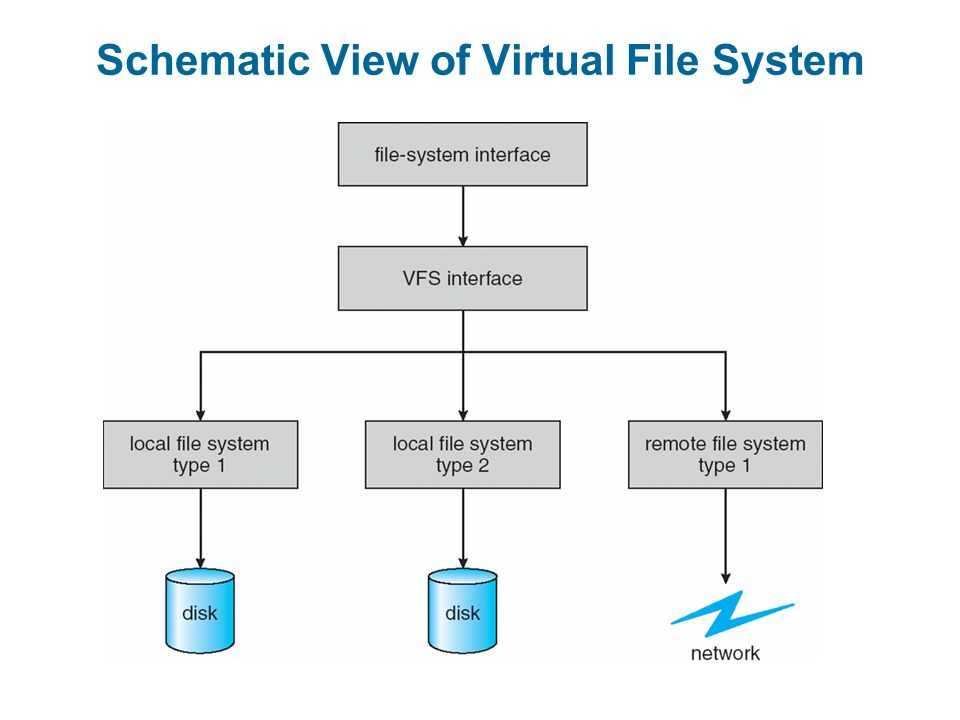
Дизайн [ править ]
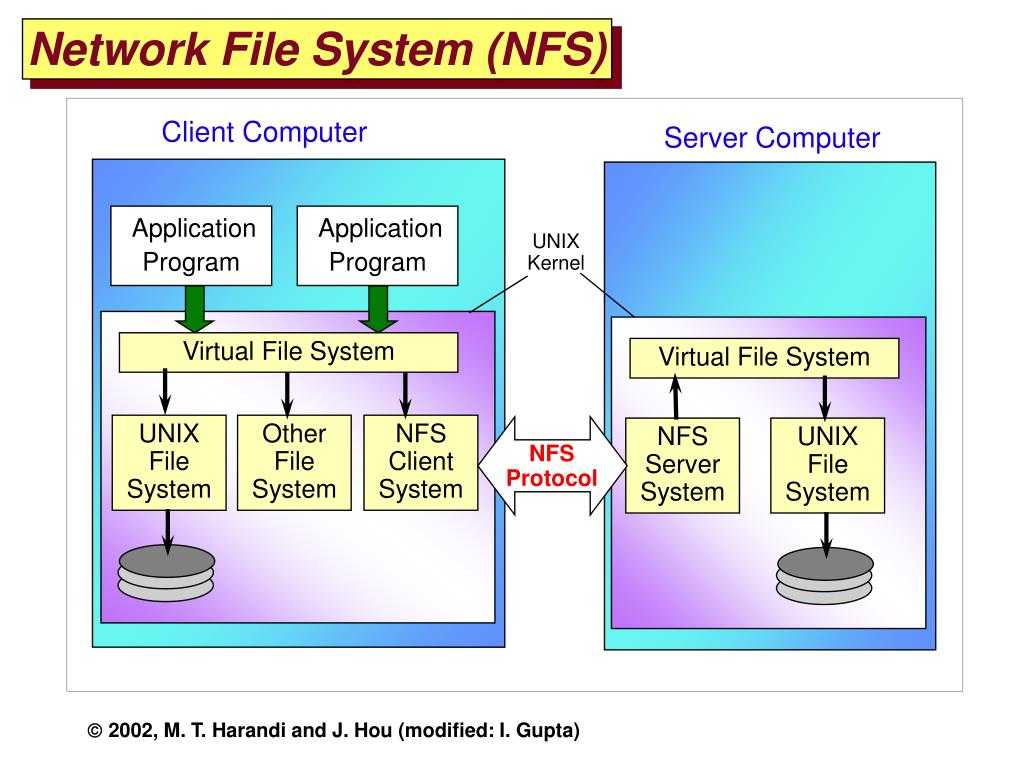
Файловая система Google предназначена для межсистемного взаимодействия, а не для межсистемного взаимодействия. Серверы фрагментов автоматически реплицируют данные.
GFS улучшена для основных потребностей Google в хранении и использовании данных (в первую очередь для поисковой системы ), которая может генерировать огромные объемы данных, которые необходимо сохранить; Файловая система Google выросла из более ранней разработки Google, BigFiles, разработанной Ларри Пейджем и Сергеем Брином на заре существования Google, когда она все еще находилась в Стэнфорде . Файлы делятся на блоки фиксированного размера по 64 мегабайта., аналогично кластерам или секторам в обычных файловых системах, которые только очень редко перезаписываются или сжимаются; файлы обычно добавляются или читаются
Он также разработан и оптимизирован для работы на вычислительных кластерах Google, узлах с высокой плотностью размещения, которые состоят из дешевых «обычных» компьютеров, что означает необходимость принятия мер предосторожности против высокой частоты отказов отдельных узлов и последующей потери данных. Другие проектные решения предполагают высокую пропускную способность данных , даже если это происходит за счет
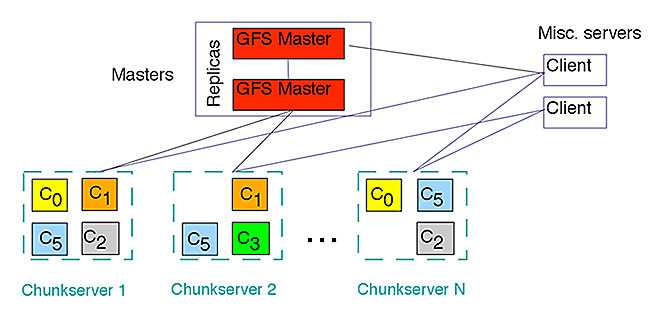
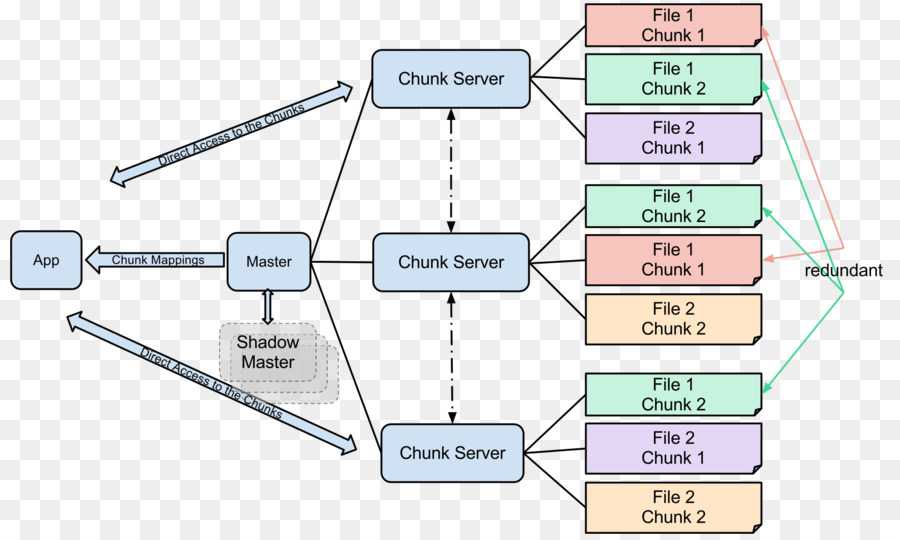
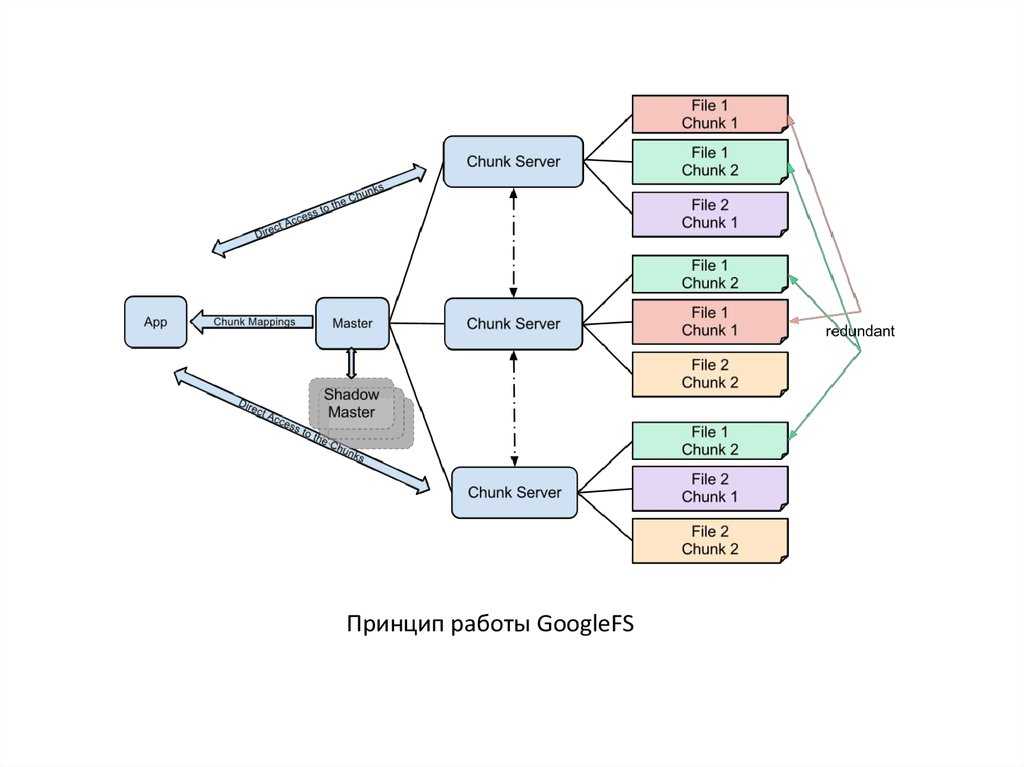
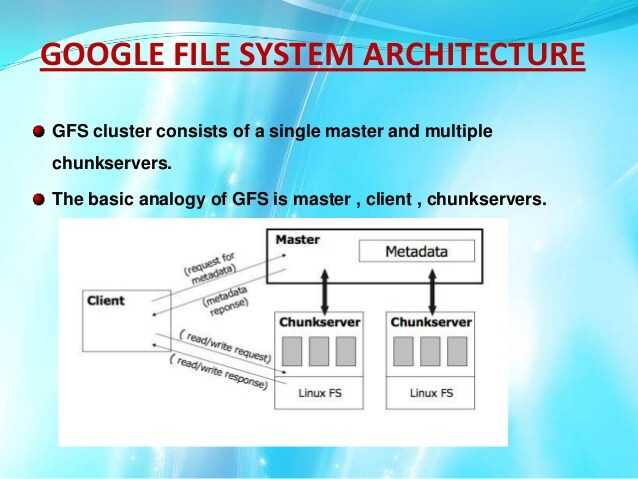
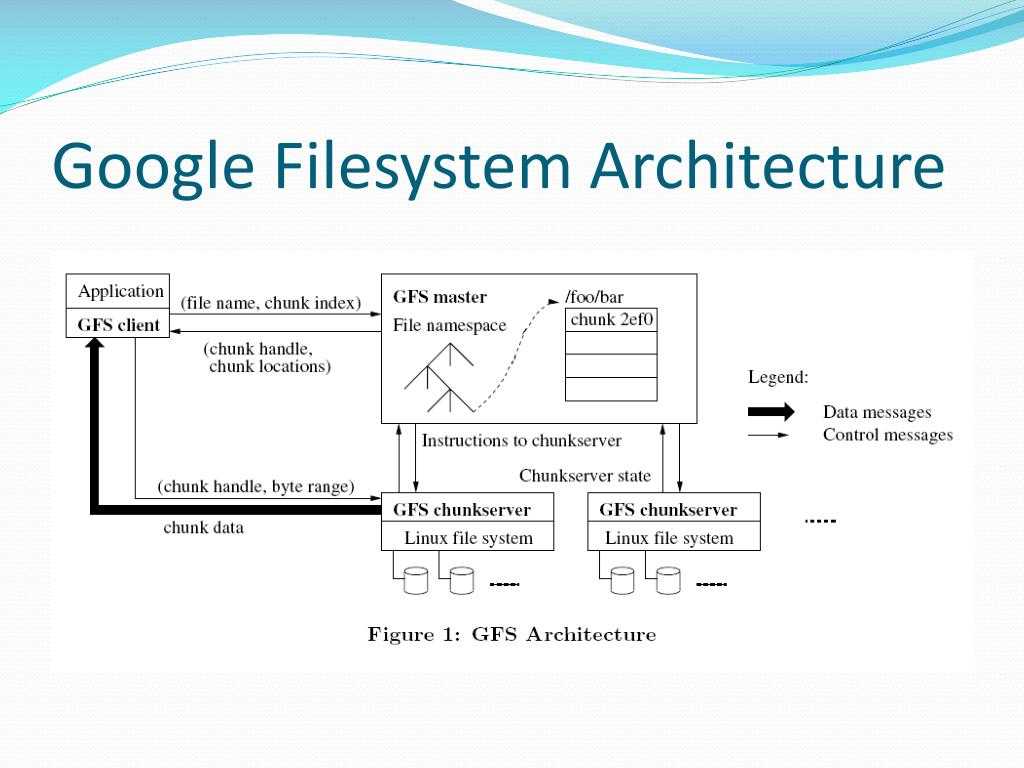
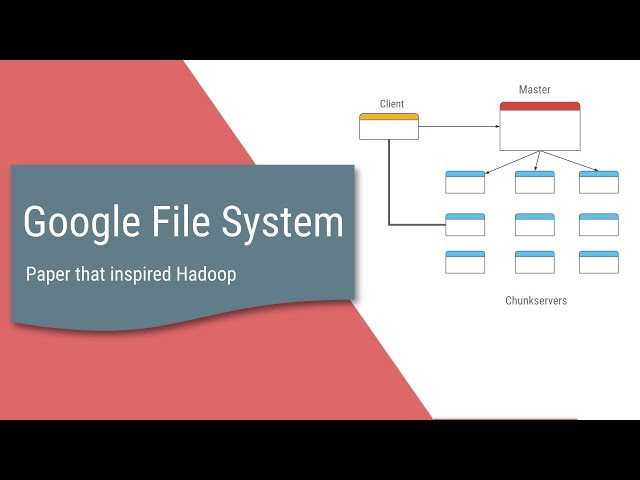
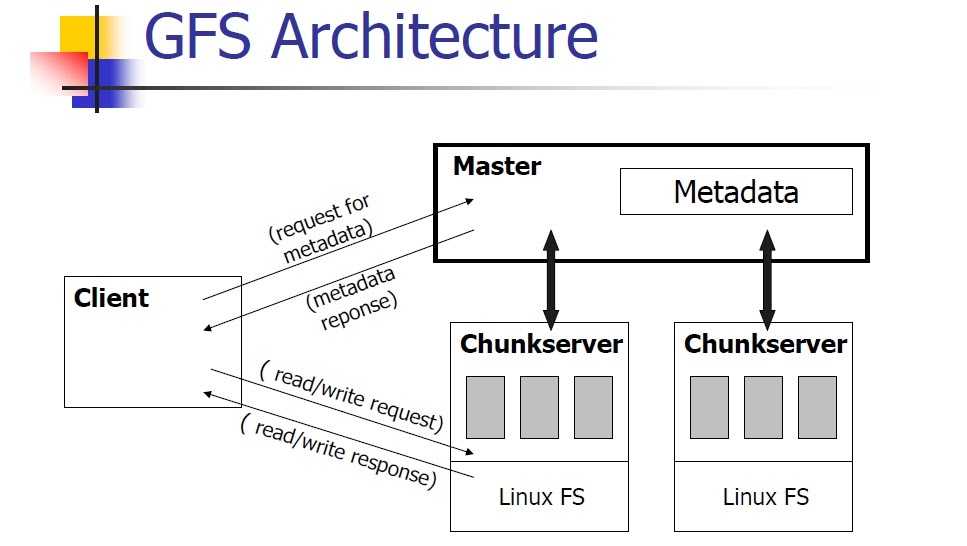
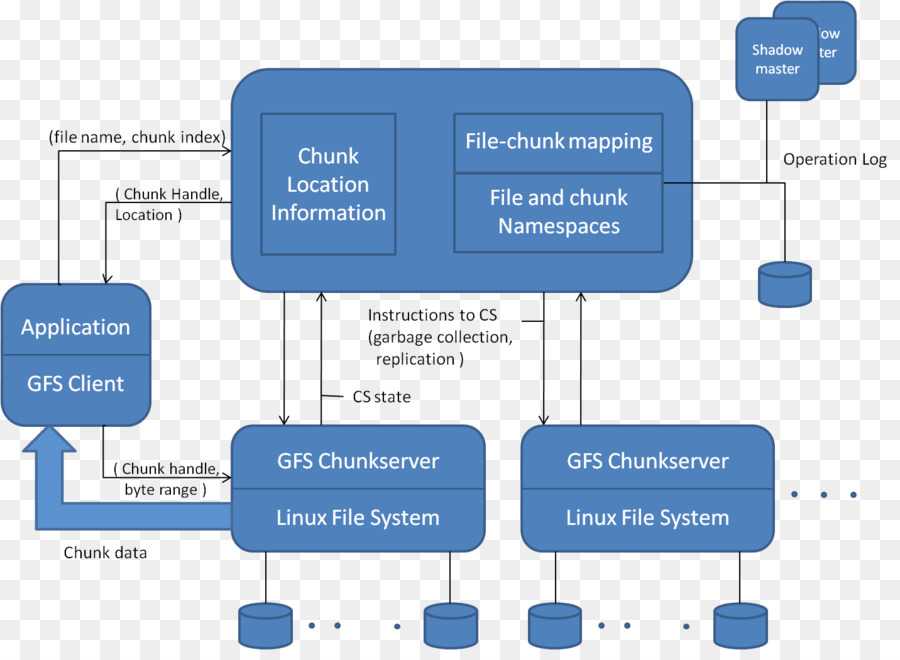
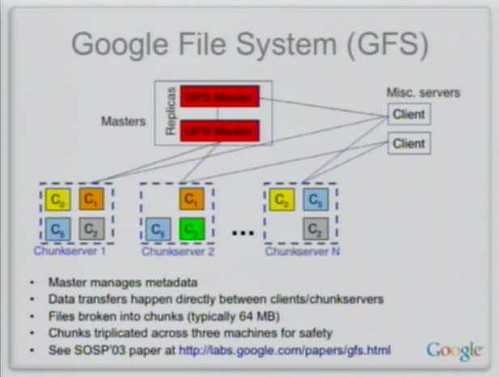
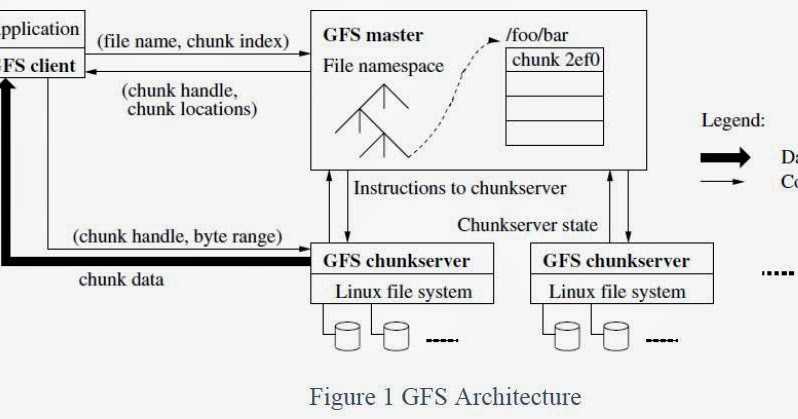
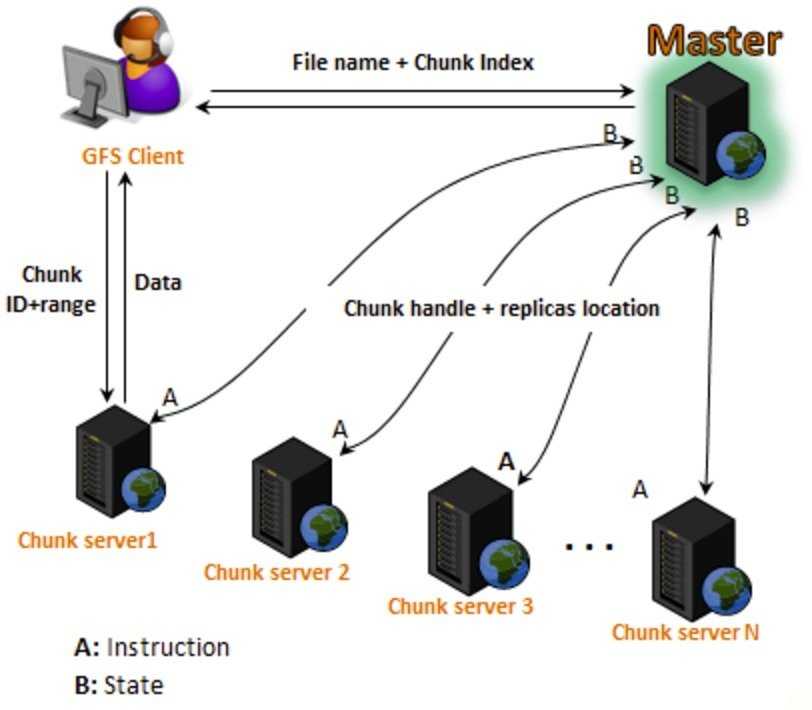
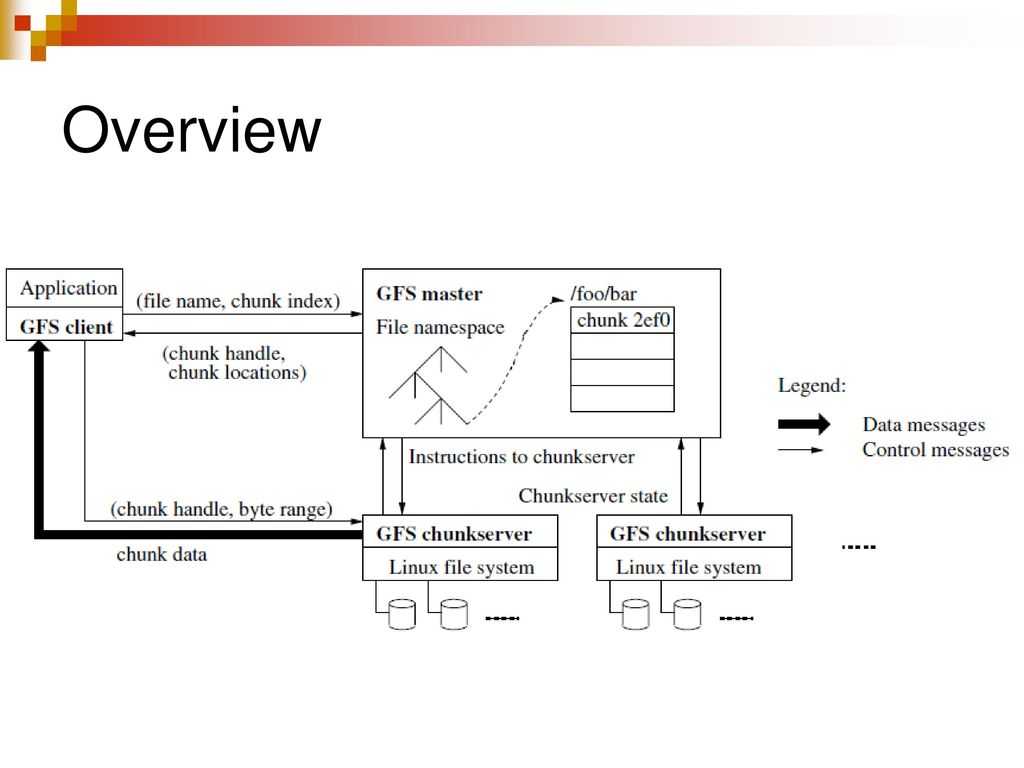
Кластер GFS состоит из нескольких узлов. Эти узлы делятся на два типа: один главный узел и несколько серверов фрагментов . Каждый файл разделен на фрагменты фиксированного размера. Серверы фрагментов хранят эти фрагменты. Каждому блоку во время создания главным узлом назначается глобально уникальная 64-битная метка, и сохраняется логическое сопоставление файлов с составляющими блоками. Каждый фрагмент реплицируется по сети несколько раз. По умолчанию репликация выполняется трижды, но это можно настроить. Файлы, пользующиеся большим спросом, могут иметь более высокий коэффициент репликации, в то время как файлы, для которых клиент приложения использует строгую оптимизацию хранилища, могут реплицироваться менее трех раз — чтобы справиться с политиками быстрой очистки мусора.
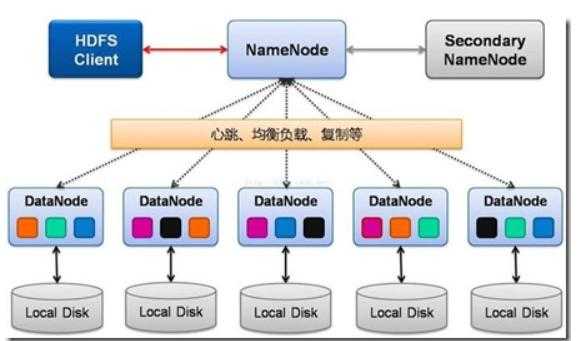
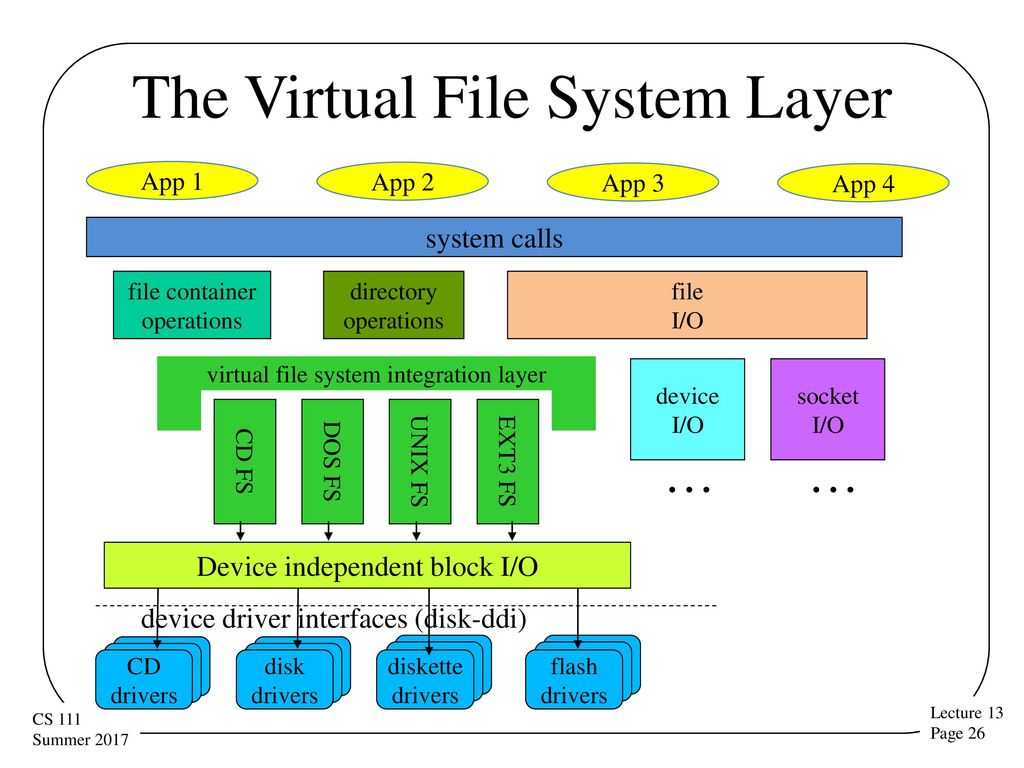

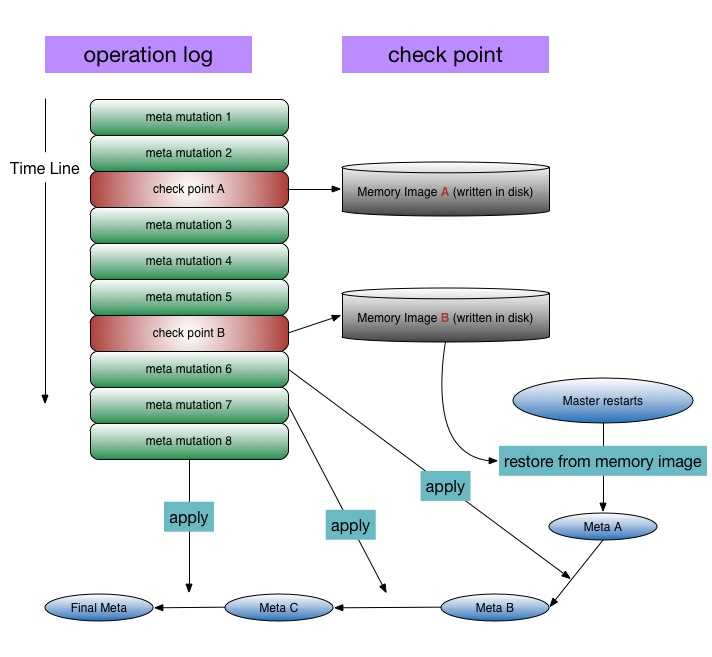
Главный сервер обычно не хранит фактические фрагменты, а скорее все метаданные, связанные с фрагментами, такие как таблицы, отображающие 64-битные метки в местоположения фрагментов и файлы, которые они составляют (сопоставление файлов с фрагментами), местоположения копий фрагментов, какие процессы читают или записывают в конкретный фрагмент или делают «снимок» фрагмента в соответствии с его репликацией (обычно по инициативе главного сервера, когда из-за сбоев узла число копий чанка меньше установленного числа). Все эти метаданные поддерживаются в актуальном состоянии за счет того, что главный сервер периодически получает обновления от каждого сервера фрагментов («сообщения Heart-beat»).
Разрешения на внесение изменений обрабатываются системой ограниченных по времени истекающих «договоров аренды», при которых главный сервер предоставляет разрешение процессу на ограниченный период времени, в течение которого главный сервер не будет предоставлять другим процессам разрешение на изменение фрагмента. . Модифицирующий сервер фрагментов, который всегда является основным держателем фрагментов, затем распространяет изменения на серверы фрагментов с резервными копиями. Изменения не сохраняются до тех пор, пока все серверы фрагментов не подтвердят, что гарантирует завершение и атомарность операции.
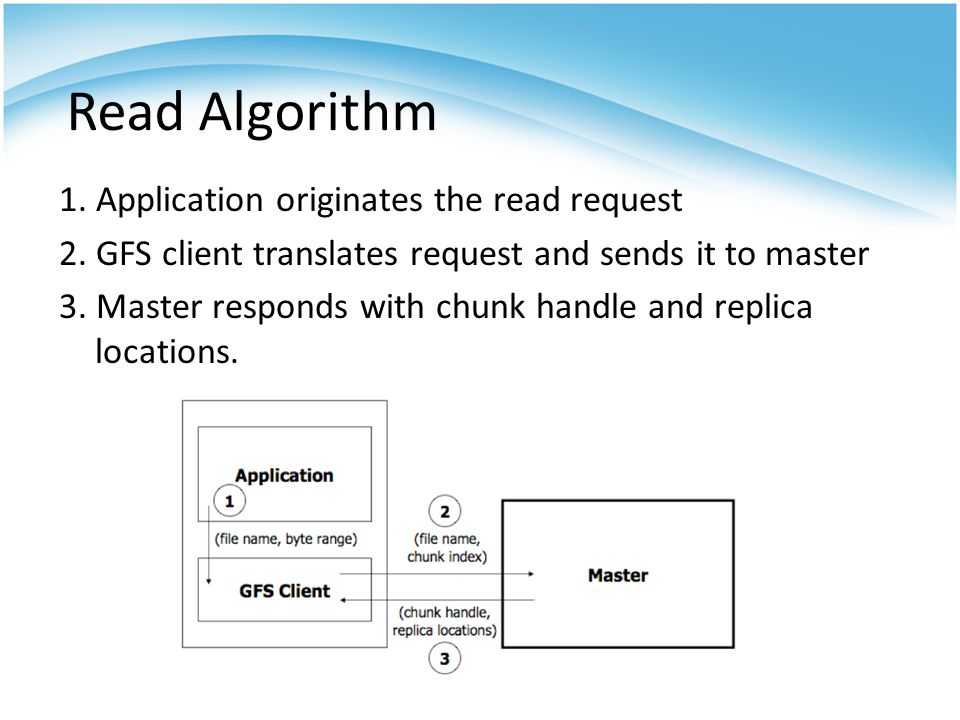
Программы получают доступ к блокам, сначала запрашивая у главного сервера расположение требуемых блоков; если с фрагментами не работают (т. е. не существует невыполненных договоров аренды), Мастер отвечает с указанием местоположений, а затем программа связывается с сервером фрагментов и получает данные напрямую (аналогично Kazaa и его суперузлам ).
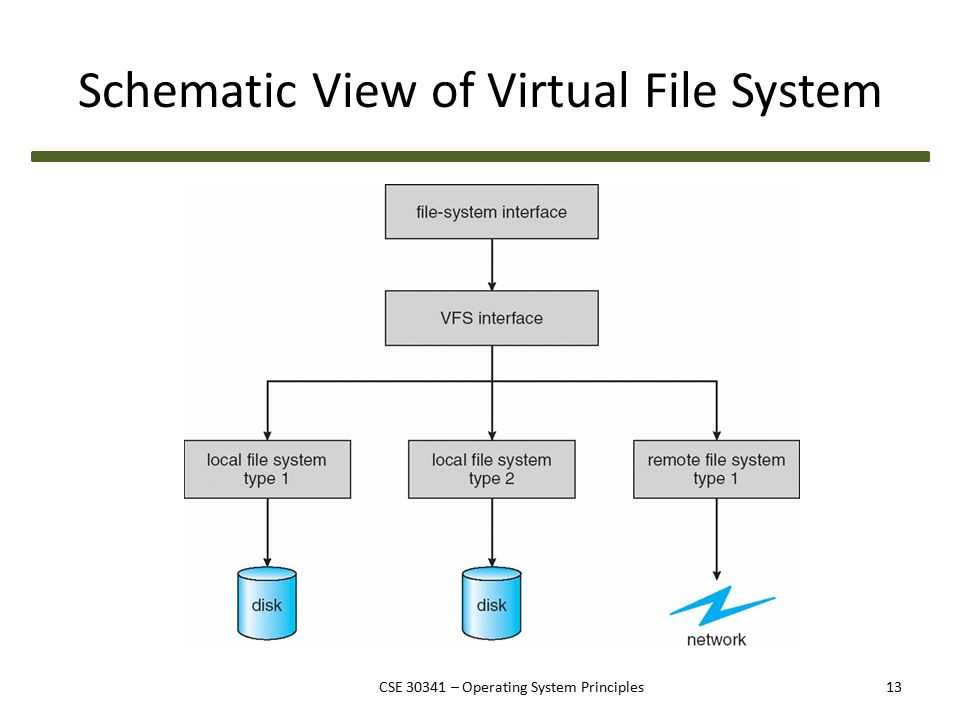
В отличие от большинства других файловых систем, GFS не реализована в ядре в качестве операционной системы , но вместо этого предоставляется как пользовательское приложение библиотеки.
Свойства системы
- Система строится из большого количества обыкновенного недорого оборудования, которое часто дает сбои. Должны существовать мониторинг сбоев, и возможность в случае отказа какого-либо оборудования восстановить функционирование системы.
- Система должна хранить много больших файлов. Как правило, несколько миллионов файлов, каждый от 100 Мб и больше. Также часто приходится иметь дело с многогигабайтными файлами, которые также должны эффективно храниться. Маленькие файлы тоже должны храниться, но для них не оптимизируется работа системы.
- Как правило, встречаются два вида чтения: чтение большого последовательного фрагмента данных и чтение маленького объема произвольных данных. При чтении большого потока данных обычным делом является запрос фрагмента размером в 1Мб и больше. Такие последовательные операции от одного клиента часто читают подряд идущие куски одного и того же файла. Чтение небольшого размера данных, как правило, имеет объем в несколько килобайт. Приложения, критические по времени исполнения, должны накопить определенное количество таких запросов и отсортировать их по смещению от начала файла. Это позволит избежать при чтении блужданий вида назад-вперед.
- Часто встречаются операции записи большого последовательного куска данных, который необходимо дописать в файл. Обычно, объемы данных для записи такого же порядка, что и для чтения. Записи небольших объемов, но в произвольные места файла, как правило, выполняются не эффективно.
- Система должна реализовывать строго очерченную семантику параллельной работы нескольких клиентов, в случае если они одновременно пытаются дописать данные в один и тот же файл. При этом может случиться так, что поступят одновременно сотни запросов на запись в один файл. Для того чтобы справится с этим, используется атомарность операций добавления данных в файл, с некоторой синхронизацией. То есть если поступит операция на чтение, то она будет выполняться, либо до очередной операции записи, либо после.
- Высокая пропускная способность является более предпочтительной, чем маленькая задержка. Так, большинство приложений в Google отдают предпочтение работе с большими объемами данных, на высокой скорости, а выполнение отдельно взятой операции чтения и записи, вообще говоря, может быть растянуто.
Файлы в GFS организованы иерархически, при помощи каталогов, как и в любой другой файловой системе, и идентифицируются своим путем. С файлами в GFS можно выполнять обычные операции: создание, удаление, открытие, закрытие, чтение и запись. Более того, GFS поддерживает резервные копии, или снимки (snapshot). Можно создавать такие резервные копии для файлов или дерева директорий, причем с небольшими затратами.
Google Cloud scales because Google scales
Before we dive into how storage services operate, it’s important to understand the single infrastructure that supports both Cloud and Google products. Like any well-designed software system, all of Google is layered with a common set of scalable services. There are three main building blocks used by each of our storage services:
-
Colossus is our cluster-level file system, successor to the Google File System (GFS).
-
Spanner is our globally-consistent, scalable relational database.
-
Borg is a scalable job scheduler that launches everything from compute to storage services. It was and continues to be a big influence on the design and development of Kubernetes.
These three core building blocks are used to provide the underlying infrastructure for all Google Cloud storage services, from Firestore to Cloud SQL to Filestore, and Cloud Storage. Whenever you access your favorite storage services, the same three building blocks are working together to provide everything you need. Borg provisions the needed resources, Spanner stores all the metadata about access permissions and data location, and then Colossus manages, stores, and provides access to all your data.

Google Cloud takes these same building blocks and then layers everything needed to provide the level of availability, performance, and durability you need from your storage services. In other words, your own applications will scale the same as Google products because they rely on the same core infrastructure based on these three services scaling to meet your needs.