
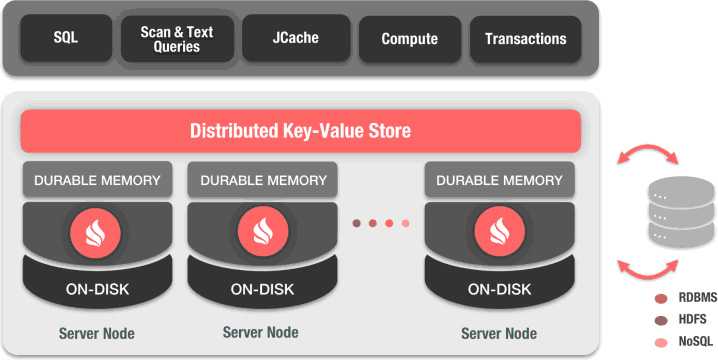
BigMemory Support
Traditionally JVM has been very good with Garbage Collection (GC). However, when running with large amounts of memory available, GC pauses can get very long. This generally happens because GC now has a lot more memory to manage and often cannot cope without stopping your application completely (a.k.a. lock-the-world pauses) and allowing itself to catch up. In our internal tests with heap size set to 60G or 90G GC pauses some times were as long as 5 minutes. Traditionally this problem was solved by starting multiple JVMs on the same physical box, but that does not always work very well as some applications want to collocate large amounts of data in one JVM for faster processing.
![]()
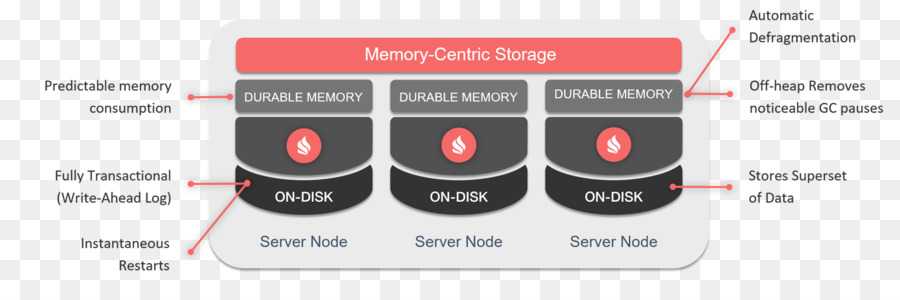
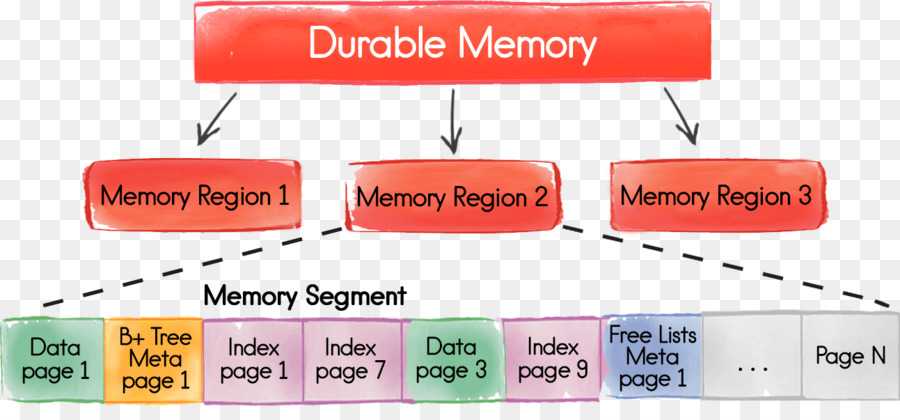
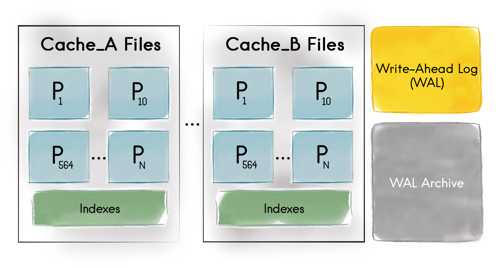
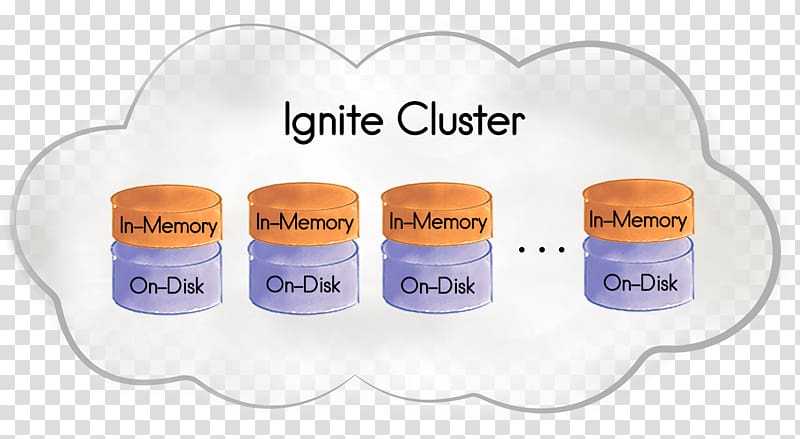
To mitigate large GC pauses, GridGain supports BigMemory with data allocated off-heap instead of on-heap. Thus, the JVM GC does not know about it and does not slow down. You can start your Java application with a relatively small heap, e.g. below 512M, and then let GridGain utilize hundreds of gigabytes of memory as off-heap data cache. Whenever data is first accessed, it gets cached in the on-heap memory. Then, after a certain period of non-use, it gets placed into off-heap memory cache. If your off-heap memory gets full, the least used data can be optionally evicted to the disk overflow store, also called swap store.
One of the distinguishing characteristics of GridGain off-heap memory is that the on-heap memory foot print is constant and does not grow with the size of your data. Also, an off-heap cache entry has very little overhead, which means that you can fit more data in memory. Another interesting feature of GridGain is that both primary and secondary indices for SQL can be optionally kept in off-heap memory as well.
Speed Only vs. Speed + Scalability of In-Memory Database vs In-Memory Data Grid
One of the crucial differences between In-Memory Data Grids and In-Memory Databases lies in the ability to scale to hundreds and thousands of servers. That is the In-Memory Data Grid’s inherent capability for such scale due to their MPP architecture, and the In-Memory Database’s explicit inability to scale due to fact that SQL joins, in general, cannot be efficiently performed in a distribution context.
It’s one of the dirty secrets of In-Memory Databases: one of their most useful features, SQL joins, is also is their Achilles heel when it comes to scalability. This is the fundamental reason why most existing SQL databases (disk or memory based) are based on vertically scalable SMP (Symmetrical Processing) architecture unlike In-Memory Data Grids that utilize the much more horizontally scalable MPP approach.
It’s important to note that both In-Memory Data Grids and In-Memory Database can achieve similar speed in a local non-distributed context. In the end — they both do all processing in memory.
But only In-Memory Data Grids can natively scale to hundreds and thousands of nodes providing unprecedented scalability and unrivaled throughput.
In-Memory Database
In-Memory Database (IMDB) is a full-featured standalone database management system that primarily relies on RAM (Random Access Memory) for computer data storage. In other words, rather than employing a disk storage mechanism, it uses RAM.
The rationale is simple: The Hard Disk Drive (HDD) which is based on magnetic storage technology first introduced by IBM in 1956 is an order of magnitude slower than RAM. IMDBs are designed to first achieve minimal response time by eliminating the need to access the disk, and second for data scalability.
They are however limited in terms of application scalability. Some IMDBS require customers to rip & replace their existing databases. They may also be limited to the types of data models stored. Depending on how data is stored, which can be a row or columnar store, In-Memory databases can provide a fast response time for write or read-intensive workflows.
In-Memory SQL Queries
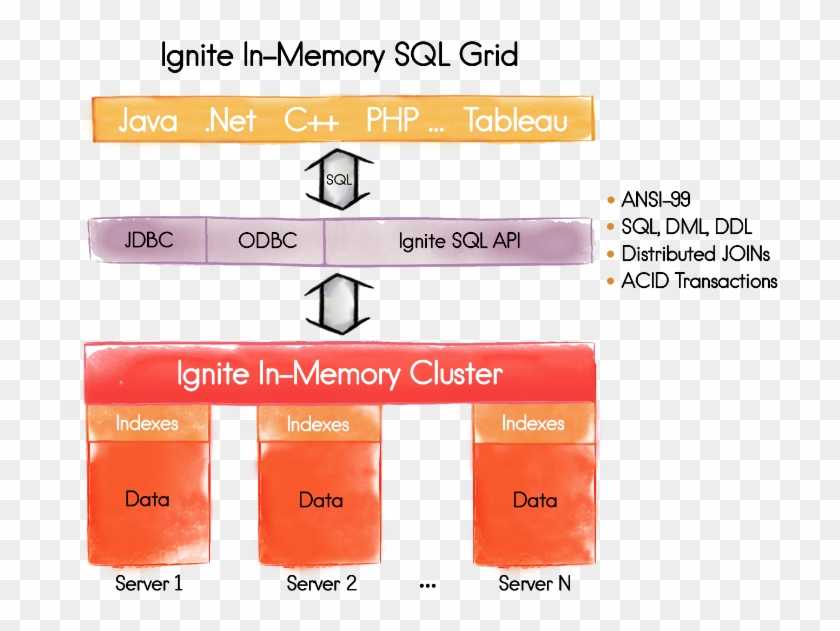
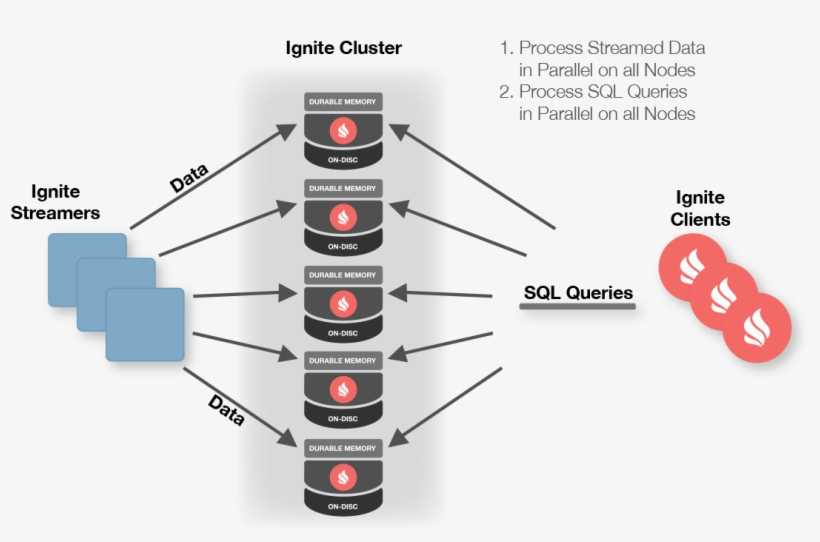
What use would be from caching all the data in memory if you could not query it? The in-memory platform should offer a variety of different ways to query its data, such as standard SQL-based queries or Lucene-based text queries.
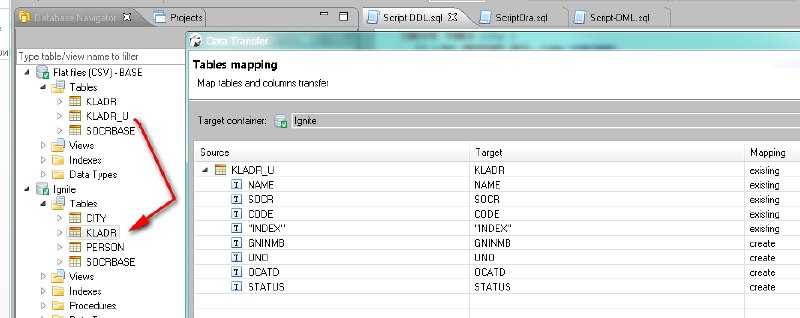
The JDBC driver implementation lets you to query distributed data from the GridGain cache using standard SQL queries and the standard JDBC API. It will automatically get only the fields you actually need from the objects stored in cache.
![]()
The GridGain SQL query type lets you perform distributed cache queries using standard SQL syntax. There are almost no restrictions as to which SQL syntax can be used. All inner, outer, or full joins are supported, as well as rich set of SQL grammar and functions. The ability to join different classes of objects stored in cache or across different caches makes GridGain queries a very powerful tool. All indices are usually kept in memory resulting in very low latencies for the execution of queries.
Text queries are available when you are working with unstructured text data. GridGain can index such data with the Lucene or H2Text engine to let you query large volumes of text efficiently.
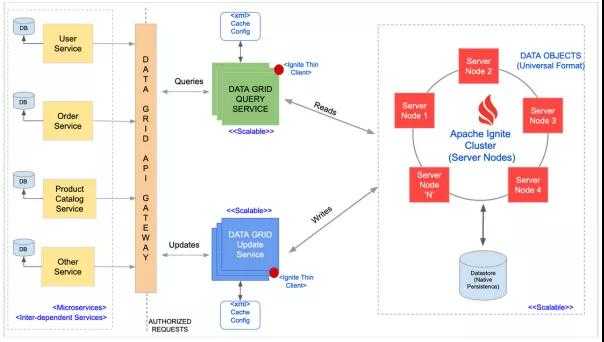


If there is no need to return result to the caller, all query results can be visited directly on the remote nodes. Then all the logic is performed directly on the remotely queried nodes without sending any queried data to the caller. This way analytics can be run directly on structured or unstructured data with in-memory speed and low latencies. At the same time GridGain provides applications and developers a familiar way to retrieve and analyze the data.
Here’s the quick example. Notice how Java code looks 100% identical as if you talk to a standard SQL database – yet you are working in in-memory data platform:
// Register JDBC driver.
Class.forName("org.gridgain.jdbc.GridJdbcDriver");
// Open JDBC connection.
conn = DriverManager.getConnection(
"jdbc:gridgain:/ / localhost/" + CACHE_NAME,
configuration()
);
// Create prepared statement.
PreparedStatement stmt = conn.prepareStatement(
"select name, age from Person where age >= ?"
);
// Configure prepared statement.
stmt.setInt(1, minAge);
// Get result set.
ResultSet rs = stmt.executeQuery();
Убиваем мечту
Теперь переходим к тому, из-за чего всё затевалось, я создаю чудесную, молниеносную, волшебную In-Memory таблицу с DURABILITY = SCHEMA_ONLY и даже вставляю в неё одну запись:
Ну и посмотрим, что у нас вставилось и сколько теперь файлы занимают на диске:
Воу, 105 мегабайт на диске для хранения 1 записи? Ну, ладно, я, в общем, готов с этим смириться — ведь больше расти не будет, правильно? Нет, не правильно. Для демонстрации я запущу вот это:
Господа, делайте ваши ставки! Что произойдёт с размером файлов после выполнения десяти чекпоинтов? Я бы зуб поставил, что ничего (и хорошо, что не поставил):
Но ведь это же не может быть правдой? У меня SCHEMA_ONLY-таблица с одной записью! Так, ладно. Насколько же глубока кроличья нора? В , что нужно планировать место в размере размер in-memory таблицы * 4, где-то я видел, что нужно обеспечить свободное место в объём ОЗУ, доступного SQL Server, * 4. Давайте попробуем.
Ваши ставки?
Такие дела. In-Memory таблица с одной записью (которая даже не изменяется), оказывается может занимать на диске столько места, сколько доступно на этом диске.
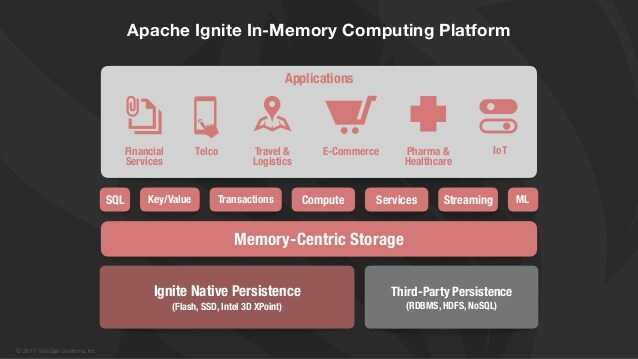
In-Memory Data Grid
In-Memory Data Grid (IMDG) is a simple to deploy, highly distributed, and cost-effective solution for accelerating and scaling services and applications.
It is a high throughput and low latency data fabric that minimizes access to high-latency, hard-disk-drive-based or solid-state-drive-based data storage.
The application and the data co-locate in the same memory space, reducing data movement over the network and providing both data and application scalability. Some in-memory data grids actually support any data model which can be directly ingested to the data grid (multimodel store) from real-time data sources or copied from an RDBMS, NoSQL, or other data storage infrastructure into RAM where processing is much faster.

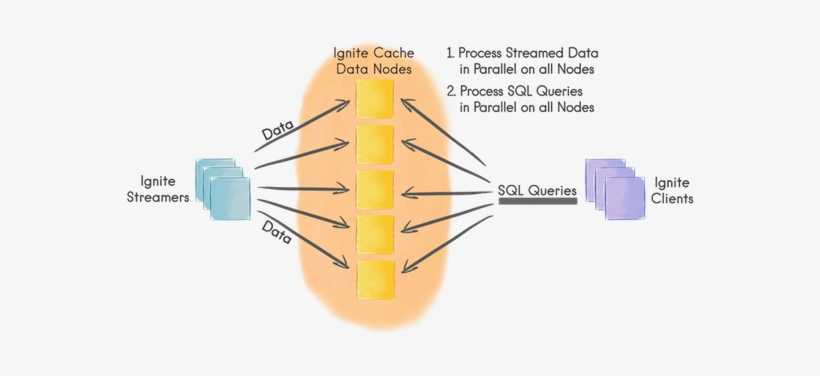



Some data grids also provide a unified API to access data from external databases and data lakes, and in essence expand the data managed to petabytes, while accelerating queries and analytics.
This is a unique capability, and you can read more about accessing external databases.
Срываем покровы
Вам, наверняка интересно почему так получается. На самом деле, мне тоже интересно, почему так получается со SCHEMA_ONLY-таблицей. В целом, на msdn есть отличная статья про Durability Memory-Optimized таблиц (а если вам нужно детально разобраться с тем как устроен In-Memory OLTP, есть отличный whitepapper от Kalen Delaney). И, справедливости ради, нигде не написано, что для SCHEMA_ONLY таблиц поведение будет отличаться.
Ключевая, для меня, фраза в статье (хотя, на мой взгляд, она не передаёт все нюансы):
Исходя из написанного здесь (там про FILESTREAM) и собственного горького опыта, речь не столько о самих бэкапах и чекпоинтах (ВАЖНО! Не делайте чекпоинты без бэкапа журнала транзакций в полной модели восстановления, чтобы вызвать сборщик мусора — ситуация будет становиться только хуже), сколько о том, что для того, чтобы файлы могли совершить «transition through the phases» нужно чтобы тот VLF, в котором они были созданы, был помечен как неактивный. Ну ладно, скажете вы, это же ерунда — бэкапы журнала транзакций в полной модели восстановления у вас снимаются регулярно, а в простой модели восстановления и волноваться не о чем
И я скажу вам да, но нет
Ну ладно, скажете вы, это же ерунда — бэкапы журнала транзакций в полной модели восстановления у вас снимаются регулярно, а в простой модели восстановления и волноваться не о чем. И я скажу вам да, но нет.
Давайте посмотрим как это выглядит:
Повторим эксперимент. В одной сессии откроем транзакцию:
А во второй выполним:
Ой, в простой модели восстановления файловая группа для In-Memory продолжает расти, если что-то мешает «переводу» нужного VLF в статус «неактивный». Это может быть незакрытая транзакция, репликация, какой-нибудь REBUILD индексов — да много можно чего придумать.
В полной модели восстановления у вас, помимо перечисленного, может быть настроена Availability Group.
Replace Database vs. Change Application
Apart from scalability, there is another difference that is important for uses cases where In-Memory Data Grids or In-Memory Database are tasked with speeding up existing systems or applications.
An In-Memory Data Grid always works with an existing database providing a layer of massively distributed in-memory storage and processing between the database and the application. Applications then rely on this layer for super-fast data access and processing. Most In-Memory Data Grids can seamlessly read-through and write-through from and to databases, when necessary, and generally are highly integrated with existing databases.
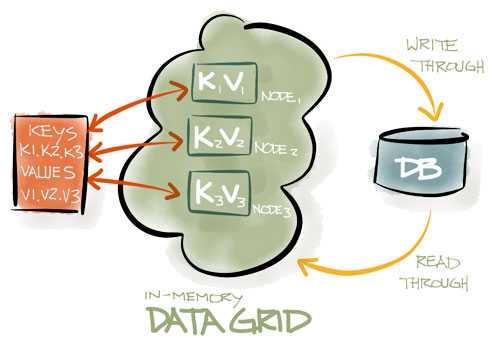
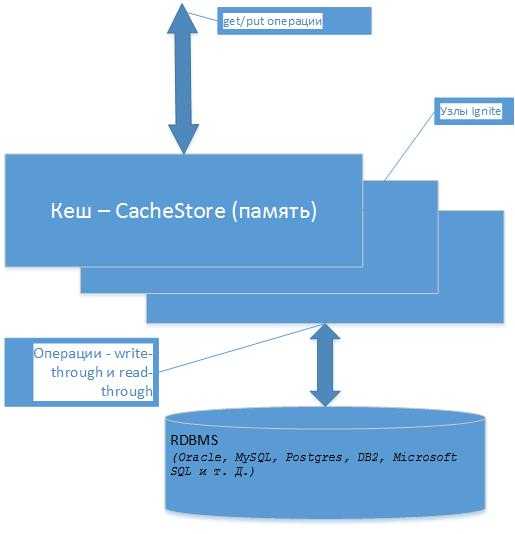
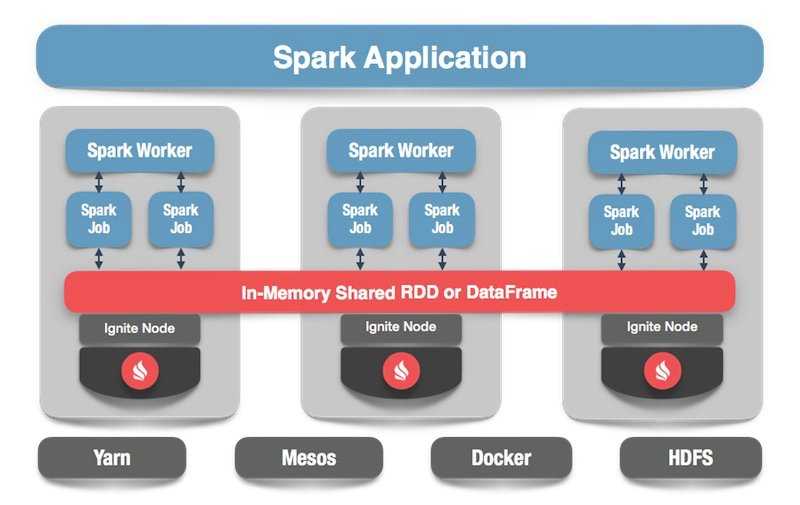

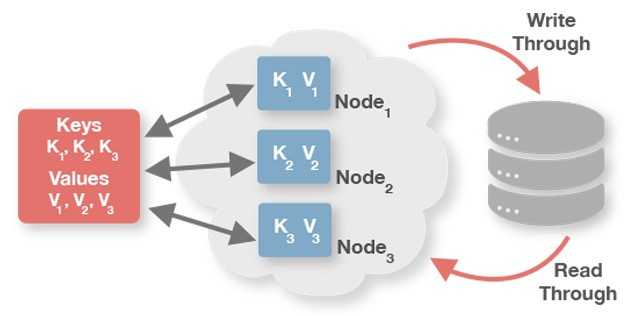
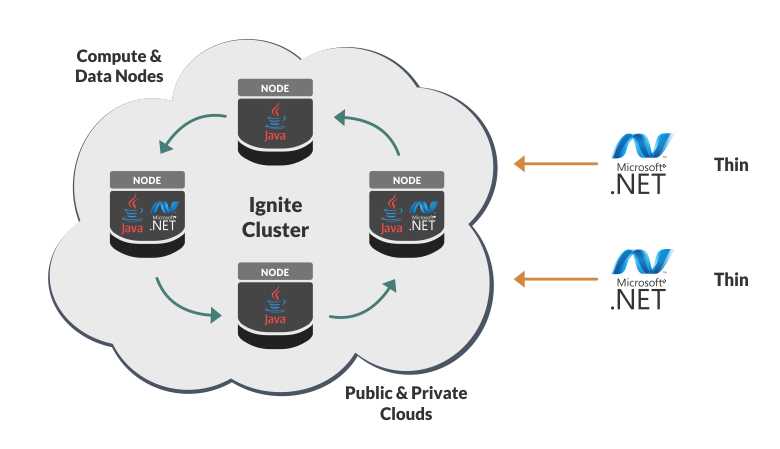
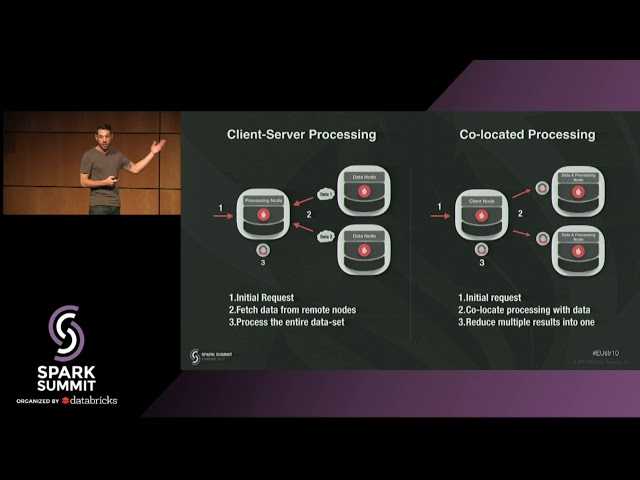
In exchange — developers need to make some changes to the application to take advantage of these new capabilities. The application no longer “talks” SQL only, but needs to learn how to use MPP, MapReduce or other techniques of data processing.
In-Memory Databases provide almost a mirror opposite picture: they often require replacing your existing database (unless you use one of those In-Memory “options” to temporary boost your database performance) – but will demand significantly less changes to the application itself as it will continue to rely on SQL (albeit a modified dialect of it).
In the end, both approaches have their advantages and disadvantages, and they may often depend in part on organizational policies and politics as much as on their technical merits.
Андрей Ершов (Dino Systems)
— Интересный технологический вопрос: выбор грид-решения на стадии проектирования системы. Что бы Вы посоветовали: сразу закладываться на широкий спектр функционала, предлагаемого каким-то решением, либо идти по пути постепенного усложнения — запуститься на чём-то, что попроще, и, по мере роста проекта, исследовать возможность использования более функциональных решений?
Принципы работы всех IMDG похожи, но API может отличаться. Есть даже JSR-107, который унифицирует работу с IMDG, вне зависимости от вендора. В этом случае вы можете абсолютно безболезненно перейти от одного решения к другому. Но здесь есть несколько «но».
Во-первых, этот JSR описывает только базовые вещи, вроде «положить в кэш»/«прочитать из кэша», entry processors и continuous query. Зачастую такого функционала может оказаться недостаточно, и тогда приходится использовать вендор-специфичные функции.
Во-вторых, обязательно нужно проводить функциональные и нагрузочные тесты с используемым решением, потому что разные IMDG имеют различные параметры, у некоторых дефолтные значения выставлены так, чтобы обеспечить максимальную производительность системы, но многие failure-кейсы могут обрабатываться некорректно. Опять же, переход на другое решение может подразумевать необходимость разбираться в настройках системы другого вендора.
Моя рекомендация — сразу выбрать вендора, но сначала использовать community версию, а потом заплатить за enterprise версию с техподдержкой и дополнительными фичами.
Скажу честно, выбор вендора — дело непростое, особенно, если вы первый раз имеете дело с IMDG и не до конца знаете сценарии использования IMDG в вашей системе. Хорошим подходом в данном случае будет создание PoC вашей системы с каждым из IMDG-решений.
— Так уж повелось, что чуть ли не каждое IMDG-решение позиционирует себя как самое лучшее для пользователей (если не для всех, то для многих). Можно ли в такой теме однозначно говорить о лучшем/худшем?
У меня есть большой опыт работы только с GridGain (Ignite), также я имею представление о фичах Coherence и Hazelcast. Могу сказать, что все три решения предоставляют большой функционал и имеют много общего. Если нужен key-value store с возможностью реагировать на изменения в grid, то можно смело брать любое решение. Но если вы планируете делать сложные запросы к данным, вам нужна поддержка транзакционности (с настраиваемым уровнем изоляции), сохранение данных на диск, репликация данных между дата-центрами, корректная работа в случае сетевой сегментации, сложное распределение данных по нодам, то имеет смысл изучить документацию каждого решения и выбрать подходящее для своей задачи.
— Если бы Вам в руки попала волшебная палочка, способная создать одну, но очень хорошую систему хранения данных — какую систему Вы бы заказали ей сделать?
Конечно, я как программист хочу, чтобы система была всегда доступна, вне зависимости от падения серверов и сетевых проблем, при этом чтобы она работала наиболее ожидаемым способом.
Вообще, когда речь заходит об ожиданиях о работе БД или IMDG, то говорят про consistency и freshness. Если система имеет дело с транзакциями, то ещё добавляется уровень изоляции транзакций (рекомендую к изучению доклад про CRDT на codefreeze; ). Чем выше уровень consistency и isolation, тем более предсказуемо ведёт себя система и тем проще её программировать. Самая лучшая гарантия — strict serializability (strong-1SR): это сочетание уровня изоляции транзакций serializability и уровня consistency — linearizability. Система, которая предоставляет strict serializability, и есть мечта.
Возможна ли такая система? Нас, конечно, будут интересовать распределённые системы. Тут мы вспомним CAP-теорему и скажем, что в случае CP (CA) такая система возможна и даже существует — Google Spanner. Однако, только Google может позволить себе такую систему — из-за очень высоких требований к инфраструктуре. И то приходится мириться с задержками на репликацию данных между континентами.
Возвращаясь к теме выбора IMDG: задумайтесь, какие гарантии даёт то или иное решение, не нарушают ли рекламные обещания производителя теоретические ограничения распределённых систем? Можно ли положиться на IMDG, если у вас сгорел порт на свитче, или происходит длительная сборка мусора в JVM, или трактор разорвал кабель между вашими DC?
How Does an In-Memory Data Grid Work?
An IMDG works by running specialized software on every computer in a cluster to coordinate access to data for applications. Each computer in the cluster has its own view of data and data structures in memory, but the view is shared across all other computers. The software keeps track of all data on each individual node, so that the data can be shared with any other node or any application. This orchestration hides the complexity of retrieving and updating data across the network, thus simplifying application development.
Data in an IMDG is often stored in the form of objects, such as maps, lists, and queues. Basic data types (“primitives”) like integers and floating-point numbers are included as well. Each of these objects and data types are represented as variables in an application, and the application logic references these variables as if they resided in the same computer that is running the application. This makes the programming paradigm much simpler than other in-memory technologies, as the developer does not need to include code to physically retrieve data.

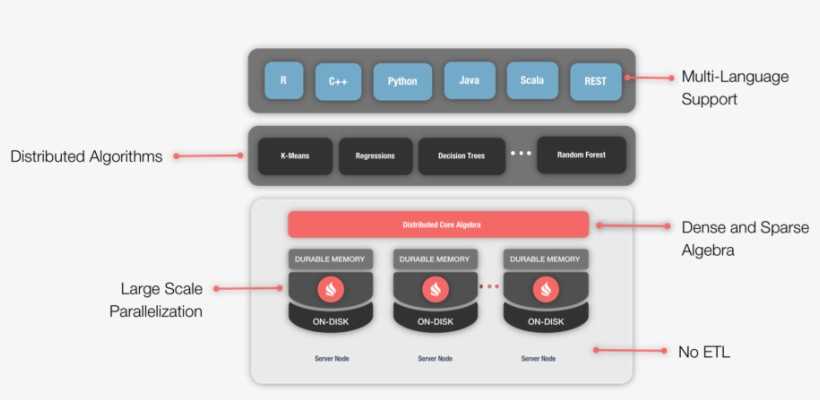

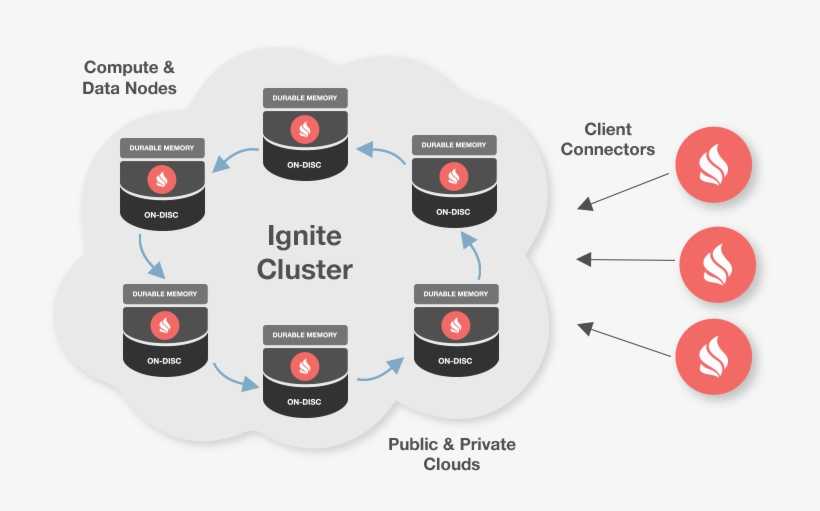
Владимир Озеров (GridGain)
— У GridGain есть бесплатная и платные версии. Скажите, с технической точки зрения, разница между ними только в наличии техподдержки и нескольких функциях (таких, как WAN-репликация), а в остальном опенсорсный Apache Ignite и «платный» GridGain одинаковы? Или же мы имеем здесь дело с моделью «Fedora vs. RHEL», когда на бесплатном варианте проходят «боевую обкатку» фичи, которые в дальнейшем в более стабильном виде войдут в платную поставку?
Существует три версии продукта. GridGain Professional — это кодовая база Apache Ignite плюс поддержка и оперативное внесение правок и улучшений (хотфиксы). Это критически важный для бизнеса момент, так как в open source вам никто ничего не должен, и не с кого спросить.
Кроме Professional, мы предлагаем GridGain Enterprise и GridGain Ultimate — это продукты на основе GridGain Professional с расширенным функционалом, таким как WAN-репликация, security, rolling upgrades, snapshots и т.д.
Хотфиксы сразу же попадают в master Apache Ignite, но релизятся раньше в рамках GridGain Professional. Поэтому платные пользователи получают их сразу, а бесплатные — либо ждут очередной релиз Apache Ignite, либо собирают его сами из мастера, на свой страх и риск.
Обкатку на бесплатных пользователях мы не практикуем ![]()
— Судя по всему, Apache Ignite (или, если угодно, GridGain) позиционирует себя как более широкую по функциональности версию других систем IMDG. Это и правда причина для гордости или просто маркетинговый подход, чтобы выглядеть выгоднее на фоне других?
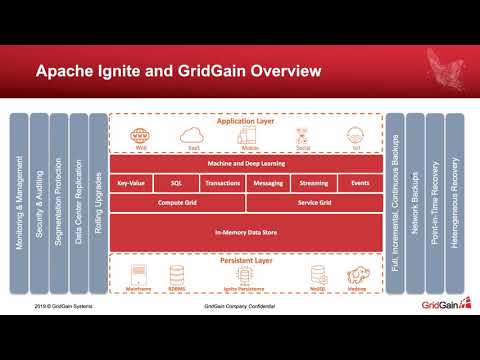
Упрощённо, наша стратегия состоит из трёх пунктов. Первое — работаем на любой платформе и с любыми фреймворками. В нашем арсенале богатая поддержка языков Java, C# и C++, десятки интеграций — от Spring/Hibernate до Hadoop/Spark, и мы продолжаем усиливать это направление. Второе — SQL как ключевой способ доступа к данным. Это другая весовая категория по сравнению с любым key-value API. Мы активно развиваем собственный SQL-движок и JDBC/ODBC драйверы к нему. Третье — это persistence. Мы научились работать как с памятью, так и с диском. Теперь Apache Ignite — это распределённая, горизонтально масштабируемая СУБД, которая может хранить больше данных, чем позволяет ваша оперативная память.
Отсюда видно, что мы действительно ушли далеко вперед от классического термина «IMDG». Тем не менее, Apache Ignite по-прежнему остается быстрым и удобным гридом, одно другому не мешает. Ну а кто «шире» или «уже» — решать пользователям ![]()
— Проекты, которые требуют использования IMDG, практически всегда нестандартны, и решения, как архитектурные, так и технические, будут вырабатываться конкретно для проекта. На Ваш взгляд, должна ли компания, использующая в своих проектах Ignite/GridGain, обладать компетенциями на уровне технологического понимания устройства выбранного грид-решения? Необходим в штате компании специально выделенный IMDG DBA-специалист?
Очень правильный вопрос. Мы действительно сталкиваемся с дефицитом навыков применения и администрирования нашей системы, так как она слишком сильно отличается от классических СУБД, к которым все привыкли. Сейчас это во многом ложится на плечи наших solution architects. Но мы ведём многоплановую работу в данном направлении. Наш фокус — документация, тренинги и выстраивание партнерских отношений с компаниями-интеграторами. Всё это способствует распространению знаний и опыта. Думаю, в перспективе нескольких лет такие навыки станут достаточно массовыми.
Analytics and In-Memory
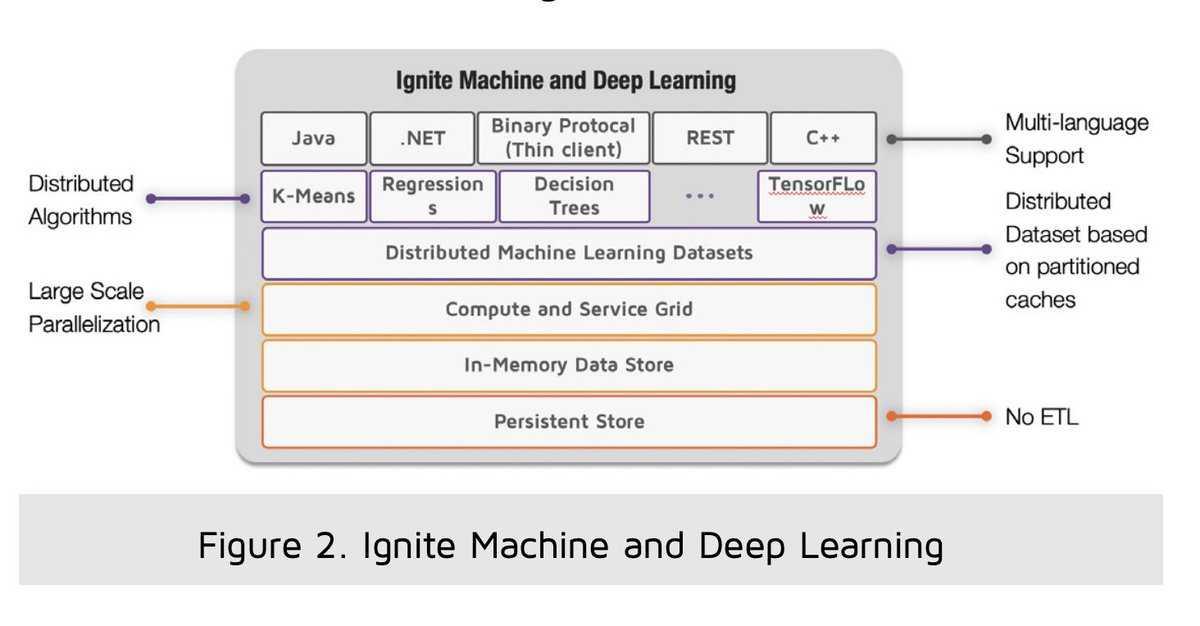
In recent years as more analytics and machine learning-powered models are being developed and deployed, In-Memory Computing solutions are increasingly bridging the gap between transactional processing and analytics.
Rather than replicating operational data for analytics resulting in data duplication and rear-view mirror analytics, a unified transactional/analytical processing, known as HTAP, augmented transactions or Translytical data platforms, powered by an In-Memory Data Grid offers real-time analytics in a fast feedback loop.
Read more about Forrester’s Translytical data platforms.
![]()
Image: Traditional vs. Unified Transactional/Analytical Processing
2021: Обновление с повышенной надежностью и производительностью
«Mail.ru Цифровые технологии» 30 сентября 2021 года выпустила вторую версию Tarantool Data Grid. В обновленной версии повысилась надежность и производительность платформы, а также упростились настройки кластера.
Tarantool Data Grid облегчает создание и поддержку бизнес-решений на платформе in-memory вычислений Tarantool. Это готовое решение, которое легко устанавливается и не требует для решения сложных бизнес-задач серьезной экспертизы разработчиков. В продукт входят инструменты для разработки приложений со встроенной производительной СУБД и средствами доступа к данным.
Tarantool Data Grid собирает, объединяет и обрабатывает данные из разных систем в реальном времени. С его помощью можно ускорить обмен информацией между медленными корпоративными системами и пользовательскими сервисами. Платформа разделяет потоки и хранит данные в оперативной памяти.
Реализация типовых сценариев и потребностей, возникающих при создании различных решений, доступна в обновленной версии «из коробки». Для разработки бизнес-приложения достаточно выполнить три шага: описать модель объекта данных, задать логику объединения, запустить решение на одном сервере. Поддерживать и развивать решение может специалист без глубоких знаний в программировании — аналитик или архитектор.





Также в Tarantool Data Grid улучшена производительность, упрощены настройки кластера, появился графический редактор коннекторов и мультитенантность — возможность обособленно обслуживать независимых пользователей системы. Обновленное решение уже работает в крупных банках и торговых сетях.
|
В данной версии Tarantool Data Grid максимум готовой функциональности доступно `из коробки`. С помощью решения возможно, не вникая в код проверять целостность данных, обрабатывать ошибки и различные потребности, которые возникают при создании решений, — отметил Алексей Корякин, технический директор Tarantool. |
So What’s the Difference?
While In-Memory Data Grids share many of the features of In-Memory Databases, there are important differences.
One significant difference is that with an In-Memory Data Grid you can co-locate the business logic (application) with the data. With an In-Memory Database, the engine running the business logic or models resides on an application (or client) while the data resides on the server-side. This is not semantic. In the latter case, the data must travel over the network, which is significantly slower than running in the same memory space (with the added network overhead).
This also affects the scalability factor. While IMDBs can handle data scalability, In-Memory Data Grids’ distributed design allows complete scalability of both data and application load by simply adding a new node to the cluster.
Other differences have to do with the data type. While IMDBs usually handle structured data, some IMDGs also support semi-structured and unstructured data. And finally, some IMDGs seamlessly integrate with machine and deep learning frameworks.
So Where Do We Go From Here? In-Memory Data Grids and Computing To the Cloud!
In-Memory Data Grids are no longer enough. The market requires evolving to advanced In-Memory Computing Platforms that increasingly reside in the cloud.
Last year Gartner published new research arguing that the future of database management is Cloud. Their message: on-premise is the new legacy. Cloud is the future.
All organizations, big and small, will be using the cloud in increasing amounts. Even the large organizations that will maintain on-premise systems will move into a hybrid configuration supporting both cloud and on-premise. What does it mean for you? Make sure your applications and services can run anywhere – on-premise, in the cloud, in multi-clouds, and in any hybrid configuration.
What is an In-Memory Data Grid?
The goal of an In-Memory Data Grid (IMDG) is to provide extremely low latency access to, and high availability of, application data by keeping it in memory and to do so in a highly parallelized way. By loading terabytes of data into memory, an IMDG is able to support most of the Big Data processing requirements. At a very high level an IMDG is a distributed key-value object store similar in its interface to a typical concurrent hash map. You store and retrieve objects using keys.
Unlike systems where keys and values are limited to byte arrays or strings, an IMDG can have any application domain object as either a value or a key. This provides tremendous flexibility: exactly the same object your business logic is using can be kept in the data grid – without the extra step of marshaling and de-marshaling. It also simplifies the use of the data grid because you can in most cases interface with the distributed data store like with a simple hash map.
Being able to work with domain objects directly is one of the main differences between IMDGs and In-Memory Databases (IMDB). With the latter, users still need to perform Object-To-Relational Mapping (ORM) which typically adds significant performance overhead and complexity. With in-memory data grids this is avoided.