
Гиперконвергенция для помощи бизнесу
Благодаря тому, что интегрированные гиперконвергентные комплексы включают в себя все необходимое для построения ИТ-инфраструктуры, существенно упрощаются все процессы, связанные с инсталляцией, настройкой, развитием сопровождением ИТ-инфраструктуры. Это, во-первых, экономит время — развертывание системы занимает часы вместо дней. Во-вторых, снижается стоимость обслуживания инфраструктуры — большего результата удается добиться меньшим количеством системных администраторов. Вместе с тем получается добиться сокращения рисков, связанных с человеческими ошибками на этапах планирования и конфигурирования, обеспечить построение масштабных распределенных инфраструктур с десятками точек присутствия без необходимости поддержки высококвалифицированного персонала на местах.
С помощью HCI можно достаточно легко организовать надежную репликацию данных между площадками и обеспечить защиту ИТ-инфраструктуры организации на случай катастрофы. Есть у гиперконвергентных решений и другие преимущества, которые раскрываются в конкретных условиях применения. И если смотреть в целом, то, как правило, решение в пользу выбора гиперконвергентной системы на предприятии принимается по совокупности факторов, ключевой из которых — сбалансированность платформы.
«Особенно эффективны HCI в таких задачах как виртуализация рабочих мест (VDI), разворачивание локальных инфраструктур в небольших точках присутствия (склады, магазины, точки продаж и т.п.), создание песочниц для разработки и тестирования приложений, микросервисных архитектур на базе контейнеров, построения частных и гибридных облачных платформ с высокой долей автоматизации и самообслуживания и т.д.», — отметил Евгений Лагунцов, архитектор решений, руководитель направления ЦОД, Cisco Россия.
«Наш опыт показывает, что сценарий быстрого запуска ИТ-инфраструктуры или ее модернизации с помощью гиперконвергентных решений — самый ходовой. За счет универсальности систем они могут применяться в разных отраслях. Это может быть как ритейл, развивающий филиальную сеть, так и энергетическая компания, которая с помощью единой платформы обеспечивает унификацию ИТ и их обновление», — рассказал Александр Сысоев, руководитель направления вычислительной инфраструктуры ИТ-компании КРОК.
Таким образом, очевидно, что гиперконвергентные решения применимы для большинства организаций с развитой филиальной инфраструктурой, желающих минимизировать затраты и риски, связанные с внедрением и поддержкой ИТ-систем. Причем, как показывает практика, HCI успешно применяются как крупными и средними, так и небольшими компаниями. Гибкая архитектура позволяет начать с нескольких узлов, доведя их количество до десятков, сотен или даже тысяч по мере необходимости. Хотя пока что, особенно в российских условиях, существенная доля проектов на основе гиперконвергентных система приходится на крупные компании. Они реализуют подобные проекты на базе собственных дата-центров.
Особенности платформы HyperFlex
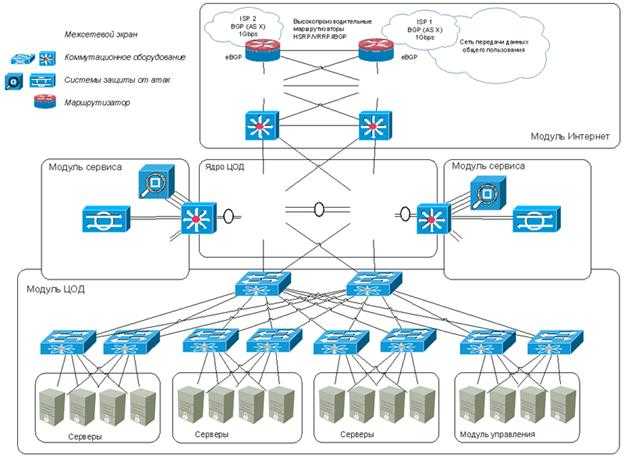
После выступления Олега Белкина, носившего общий, обзорный характер, слово взял системный инженер Cisco Евгений Лагунцов. Он подробно рассказал о технических характеристиках платформы HyperFlex. Прежде всего, гибкость масштабируемости тут обеспечивается наличием трех возможных конфигураций системы. Если вам требуется компактность, HyperFlex можно делать на основе одноюнитовых блоков Cisco HX220c. Другой тип узлов – двухюнитовые Cisco HX240c – обеспечивают построение СХД с высокой емкостью. В обоих случаях система может включать от трех до восьми узлов. Наконец, существует третья оригинальная компоновка из гибридных узлов, включающих в себя блоки Cisco HX240c и B200 (последние представляют собой обычные блейд-серверы). При такой компоновке в HyperFlex может содержаться до восьми комбинированных узлов и дополнительно до четырех вычислительных. Таким образом, заказчик получает возможность гибко настраивать систему под свои нужды.
В составе системы всегда присутствует UCS Fabric Interconnect, отвечающая за связь узлов между собой и с внешним контуром. При этом к одной паре Fabric Interconnect могут подключаться несколько кластеров HyperFlex.
Распределенная архитектура обеспечивает: удобное добавление новых ресурсов за несколько минут, линейное наращивание ресурсов, автоматическое перераспределение нагрузки данных и возможность выведения ресурсов без остановки и без потери защиты. Управление, как уже было отмечено, полностью базируется на VMware vCenter – этот инструмент обеспечивает единую систему мониторинга и сбора событий
Важно отметить и отсутствие необходимости отдельно управлять СХД и сетью SAN, а также переключаться между консолями. А если упрощается управление, то, как логично заметили эксперты Cisco, заказчик может экономить на квалифицированном персонале по обслуживанию СХД
Говоря о перспективах дальнейшего развития решений HyperFlex, Евгений Лагунцов отметил, что планируется увеличить количество доступных гипервизоров (речь может идти и о возможности контейнерной виртуализации), добавить новые сценарии применения и новые сервисы. А главное, Cisco планирует увеличить количество узлов кластера с сегодняшних восьми до 64, что автоматически переводит эти системы в новый разряд решений, пригодных для построения «тяжелых» СХД.
В плане возможных сценариев применения были названы следующие: удаленные офисы компаний и крупные региональные филиалы, удобная инфраструктура для разработки и тестирования ПО, серверная виртуализация и VDI. Что касается виртуальных десктопов, то, как заметил Евгений Лагунцов, HyperFlex изначально предназначался именно для этого сценария применения. На сегодня возможно обеспечение до 100–150 виртуальных рабочих столов одним узлом кластера. По заявлению представителей Cisco, известный российский провайдер готов попробовать HyperFlex на региональных ЦОД, но пока он ожидает появления платформы следующего поколения, когда появится возможность создавать большие кластеры до 64 узлов.
Переход в пространство ИТ-услуг
Главный результат влияния облака – смена точки зрения на ЦОД: переход от характеристик «железа» к показателям, характеризующим ИТ-услуги.
| На первый план выходит уже не способность ИТ-служб обеспечить заданное количество операций ввода-вывода, объемов хранения, показателей надежности – это требования понятные и привычные, а готовность быстро развернуть необходимую платформу для оказания ИТ-услуг и эффективно ей управлять в интересах бизнес-пользователей,- говорит Павел Карнаух. |
- «Инфраструктура как код». Эта концепция — «мягкий» способ обеспечить функционирование программно-определяемого ЦОДа. Фактически речь идет об обеспечении гибких возможностей облака в локальной инфраструктуре за счет широкой автоматизации операций. Тогда бизнес-приложения, управление инфраструктурой, инструменты для автоматизации и оркестровки услуг позволяют развертывать инфраструктуру и выделять ресурсы в реальном времени, а также поддерживать динамические рабочие задачи и оперативно реагировать меняющиеся потребности бизнес-задач. Очевидно, что подход «Инфраструктура как код» отлично соответствует идеям DevOps, самообслуживания ИТ и современным методам разработки на основе концепции Agile, включая low-code.
- Все как услуга. Консалтинговая компания Deloitte называет концепцию «Все как услуга» (Everything As A Service, EaaS) одним из наиболее мощных технологических трендов, которые определяют потребность в появлении гибких платформенных архитектур. Она подразумевает доступ к гибкому пулу ресурсов, который можно настроить и легко распределять в режиме реального времени. «Все как услуга» — это масштабируемая емкость по требованию с автоматизированной функциональность и простота управления плюс интерфейсы, которые позволяют легко интегрировать между собой поставщиков ИТ-сервисов и модели развертывания.
Дальнейшее развитие систем виртуализации и появление концепции «все как услуга» (EaaS) заставили операторов ЦОД по-новому взглянуть на понятие ресурсов, замечает Дмитрий Чиндяскин:
| На текущий момент возможна виртуализация всех физических ресурсов ЦОД, будь то канал связи (QoS, управление пропускной способностью и пр.), сервер, СХД (полноценная виртуальная машина или пул ресурсов). А учитывая наличие графических интерфейсов управления кластерами виртуализации, значительно упрощается рутинная работа администратора по управлению ресурсами, их делегированию иным подразделениям, контролю их утилизации и планированию. |
Правда, переход к EaaS – это длительный процесс. Мы находимся в самом его начале. Поэтому Дмитрий Чиндяскин предупреждает:





| Далеко не всегда внедрение подхода EaaS является панацеей и правилом для создания правильного ЦОД. Правильность для каждого конкретного заказчика должна проистекать из полноценного аудита аппаратной, сетевой и программной инфраструктур, требований корпоративных регламентов использования программного обеспечения и информационной безопасности, а также бизнес-процессов компании. |
4. Как составить требования к доступности, отказоустойчивости и производительности СХД?
На требования к СХД влияет масштаб компании
Важно знать, сколько предполагается пользователей, сколько магазинов будет подключено, насколько критичен простой в передаче данных. Как правило, крупным розничным сетям, оперирующим большим массивом ценных данных, которые необходимо хранить качественно и в полном объеме, требуются емкие и мощные решения класса Enterprise.
«В ритейле обычно нужна высокая доступность данных, – комментирует Алексей Никифоров. – Как правило, заказчик СХД смотрит на количество девяток доступности и максимальный процент выхода носителей из строя без потери информации, то есть ориентируется на то, какие потери может пережить СХД. Все вендоры уже предлагают по два блока питания, задублированный контроллер, отсутствие единой точки отказа. Но в Hitachi Vantara пошли дальше – степень отказоустойчивости некоторых классов СХД составляет 3 из 4, то есть из 4 контроллеров 3 могут выйти из строя – и система будет продолжать полноценно работать. Если необходима высокая доступность и отказоустойчивость в рамках ЦОДа, то на второй ЦОД закладываются решения репликации данных сервера. Все это учитывается при проектировании ресурсов СХД».
Но небольшим компаниям – например, нишевым производителям, локальным ритейлерам – такие масштабные и распределенные системы не нужны. Для них простой системы, длящийся три – пять часов, некритичен: данные о транзакциях все равно будут фиксироваться на онлайн-кассах, просто какое-то время не будут передаваться в CRM компании. Существенно на процессы малого бизнеса такие простои не повлияют. Поэтому решение рассчитывается на невысокий уровень критичности. Такое решение будет дешевле, чем решение с минимальным простоем, измеряемым секундами.
Высокая производительность тоже нужна не всем. Чтобы правильно рассчитать и спрогнозировать нагрузку, лучше обратиться к интегратору.
3. Какие данные планируется хранить?
На выбор СХД влияют тип и объем данных. Данные бывают неструктурированные и структурированные.
Неструктурированные – это данные, требующие обработки, – например, видеозаписи, фотографии, чертежи, схемы, архивы переписки по электронной почте, накладные, чеки и т.д.
Структурированные – базы, таблицы, вычисления и прочие аналогичные упорядоченные массивы.
В зависимости от типа хранимых данных и подбирается решение: «Например, под неструктурированные данные подойдет СХД объектного класса, где записи хранятся в виде объектов, – говорит Алексей Никифоров. – Либо можно использовать хранилища типа Hadoop (набор утилит, библиотек и фреймворк для разработки и выполнения распределенных программ), в которых можно не только хранить, но и обрабатывать большие данные. Это уже хранительно-распределительно-вычислительные системы. Возможно, под тип данных, которые планирует хранить ритейлер, нужна вовсе не СХД. Понимая, какой тип данных предполагается хранить, вендор сможет предложить оптимальное решение».
2. На что ориентироваться при выборе системы хранения данных?
В первую очередь надо ориентироваться на стратегию развития и бизнес-цели компании.
В соответствии с общей стратегией и требованиями бизнеса выстраивается ИТ-стратегия.
«Надо представлять потенциально верхний уровень роста, понимать, куда хочет двигаться компания, на каких сервисах и мощностях будет развиваться ИТ-инфраструктура, – поясняет Алексей Никифоров. – Должен быть определен четкий путь. Потом он может меняться, но общий вектор необходимо задавать сразу».






От стратегии компании зависит сайзинг системы – подбор оптимальной конфигурации и производительности с учетом роста бизнеса.
Программно-определяемое все
Принцип программной определяемости (Software Defined) подразумевает переход от жестко реализованной аппаратной архитектуры к программируемой, что дает сразу целый спектр позитивных следствий – принципиально новый уровень динамичности, гибкости и экономической эффективности соответствующих ИТ-проектов.
Группы из большого количества серверов универсальной Intel-архитектуры превратились в единый источник унифицированных вычислительных ресурсов, так что системным администраторам осталось просто следить, чтобы этих ресурсов было достаточно. Программно-определяемая СХД может эффективно и надежно работать с дисками различных поставщиков, и к тому же это могут быть диски недорого уровня. Практическая реализация данной идеи во всей полноте, правда, пока не достигнута, но направление движения очевидно. В программно-управляемых сетях передачи данных (Software Defined Network, SDN) управление передается в программируемую часть сети, а за диспетчеризацию трафика отвечают устройства, управляемые программой. В результате управление работой сети отделяется от рутинной работы по перекачиванию данных.
По данным Forrester, внедрение SDN позволяет существенно сокращать расходы на модернизацию инфраструктуры — на 68% снижаются затраты на обновление сети при внедрении стратегии ИБ с «нулевым уровнем доверия», на 37% — затраты на приобретение новых серверов и на 87% -трудозатраты на типовые задачи администрирования сетей.
| Также SDN помогает унифицировать управление политиками сетевого доступа и безопасности при переходе к гибридной или мульти-облачной модели ИТ,- подчеркивает Андрей Косенко, старший консультант по бизнес-стратегии, VMware. |
Идея унифицированного управления ИТ-ресурсами различных типов нашла отражение в обобщающей концепции Software-Defined Everything (SDE), то есть «программно-определяемое все». Главный смысл SDE заключается в возможности перенести основную часть управляющего интеллекта информационных систем в программную составляющую на базе массового недорогого аппаратного обеспечения. Помимо указанных выше программно-определяемых сущностей, появились, например, понятия, программно-определяемых рабочих мест (Software-Defined Workplace, SDW), программно-определяемой безопасности (Software-defined security, SDsec), которая базируется на виртуальных устройствах безопасности (Software-based Virtual Security Appliances) и, наконец, программно-определяемый ЦОД (Software Defined Data Center).
Термин SDDC был введен в употребление компанией VMware в 2012 году, в бытность его техническим директором. Тогда он подразумевал виртуализацию инфраструктуры ЦОД и применение определенных программных технологий для того, чтобы подняться на уровень выше конкретного аппаратного обеспечения и получить возможность автоматизации управления. За прошедшие годы концепция SDDC получила существенное развитие.
| Наиболее значимой тенденцией в области эволюции центров обработки данных я вижу реализацию концепции программно-определяемого ЦОД, при котором все компоненты (вычисление, хранение данных, сеть и безопасность) реализованы программно,- рассказывает Андрей Косенко.- Эта концепция дает ощутимые преимущества — сокращение затрат на ресурсы, улучшенную масштабируемость, эффективное использование ресурсов инфраструктуры, ускорение вывода новых услуг на рынок, прозрачность действий в сети и улучшенную модель безопасности. И самое главное — автоматизацию и простую эксплуатацию. Кроме того, программно-определяемый ЦОД освобождает бизнес от зависимости от определенного типа оборудования и необходимости развивать и поддерживать навыки персонала в разрозненных областях. |
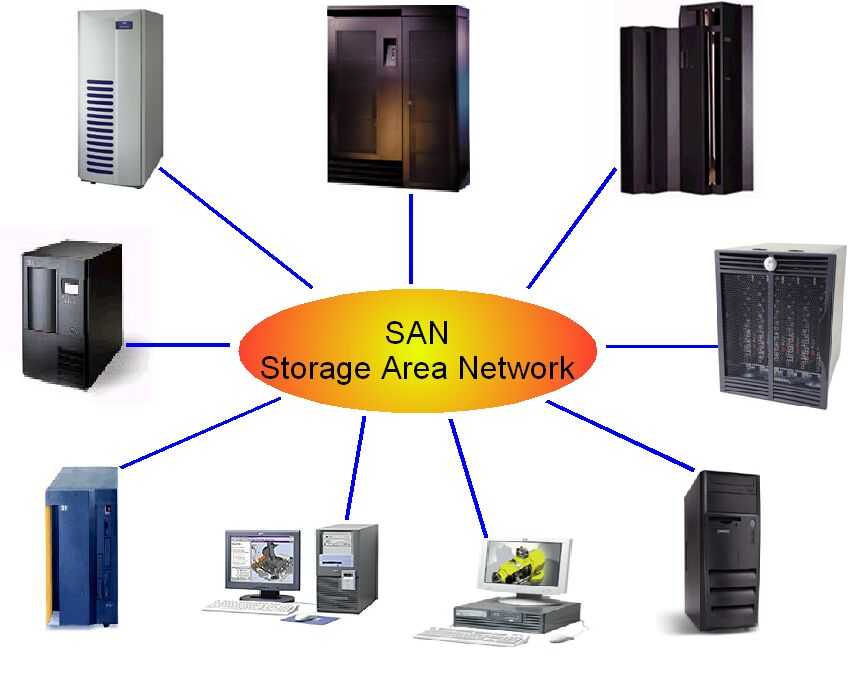
Какие бывают типы СХД?
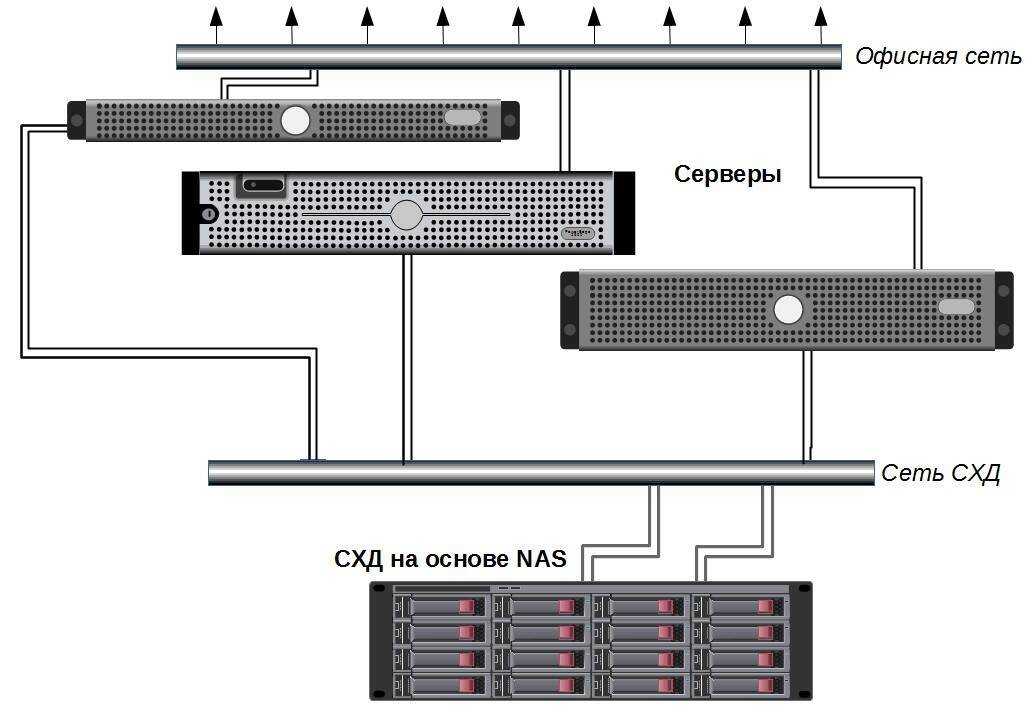
Есть три больших типа систем хранения данных: файловое хранилище, объектное хранилище и блочное хранилище.
Блочное хранилище
Работает по блочным протоколам SAN: Iscsi и Fibre Channel. Они подключаются к серверам с нарезанием томов и файловых систем для дальнейшего использования. Блок данных – это не какой-то законченный объект, а кусок фиксированного размера, содержащий некие данные. Файл может занимать несколько блоков, и, если последний из этих блоков заполнен не до конца, на его размер это не повлияет. Блочное хранилище может быть использовано любой операционной системой в качестве дискового тома этой системы, а пользователь видит этот диск в интерфейсе ОС сервера. Она, в свою очередь, может быть как физической, так и виртуальной. Однако физическим серверам в отличие от виртуальных нужны дополнительные контроллеры для того, чтобы получать доступ к исходным блокам. Преимуществом блочных систем является высокое быстродействие.
Файловые хранилища
Могут работать как с конечными пользователями (например, сотрудниками, которые со своего компьютера могут открыть файлы компании), так и с серверными мощностями. Такие хранилища внешне больше всего напоминают организацию информации в наших компьютерах: файлы вложены в папки. Доступ к данным осуществляется по file ID, содержащему имя сервера, путь к директории, а также имя искомого файла в NAS. Чаще всего в качестве протоколов доступа к файлам через NAS используют протоколы NFS (для Unix и Linux) и CIFS (для Windows). Последний является публичным вариантом более специализированного протокола SMB (Server Message Block), который использует сетевой протокол TCP/IP. Сервер файловой СХД использует внутри локальной файловой системы блочное хранилище, в то время как пользователь работает лишь с внешним протоколом, определяющим путь к файлу.
Объектное хранилище
Можно использовать в разных целях. Основные его задачи – сохранять большие объемы данных в виде объектов, которые можно моделировать и которым можно присвоить метаданные. В СХД этого типа применяются примерно такие же технологии, что и в публичном облаке (HTTP, API). Объектные хранилища легко масштабируются до объемов петабайта в одном домене, без снижения производительности. В отличие от традиционных СХД, в объектных хранилищах есть функционал управления данными – например, кастомизации метаданных и встроенной аналитики. На внешнем уровне размещены средства управления, а на внутреннем уровне каждый диск форматируется простой локальной файловой системой (например, EXT4). Это позволяет пользователю управлять функциями внешнего уровня через стандартный интерфейс прикладного программирования API, а все элементы СХД интегрированы в единый унифицированный том.




![Fc подключение к схд сервера под windows [colobridge wiki]](https://sariola.ru/wp-content/uploads/9/6/d/96da80e6886d3d79630011f8754bd5e5.jpeg)

6. Что лучше – один дорогой сервер или двадцать бюджетных?
«Ритейлеры любят дискуссии о том, что лучше – купить одну дорогую железку или много дешевых и в сумме обеспечить примерно те же самые мощности, – рассказывает Алексей Никифоров. – С точки зрения отдела закупок кажется логичнее закупить двадцать маленьких, цена которых будет существенно ниже, чем одной большой. Но мало кто думает о том, что если эти устройства начнут по очереди ломаться, как это нередко и происходит, то возникнут большие проблемы со всем остальным объемом информации, придется быстро искать, где вылетело, и оперативно устранять сбой. Это как плыть в дырявой лодке – постоянно приходится затыкать большое число дырок».
Например, если устройство имеет два контроллера, но при этом обладает низкой процессорной мощностью и слабыми возможностями отказоустойчивости, то в обычном режиме оно сможет работать и поддерживать стандартные процессы, но стоит дать большую нагрузку – и все посыпется. А ведь сервис рассчитан на использование двадцати устройств одновременно, и если два из них отвалились – кусок данных окажется недоступным. Чтобы починить или заменить, нужно будет найти именно две недоступные. В итоге такое решение оказывается нерабочим. ИТ-директор сдвигает его на другие задачи и закупает новое железо. Поэтому специалисты Hitachi Vantara рекомендуют покупать одно дорогое надежное устройство.
Чем решения Hitachi Vantara отличаются от других решений на рынке?
В классе Enterprise решения Hitachi Vantara обладают самой высокой производительностью и надежностью. Например, Hitachi Virtual Storage Platform серии 5000 (VSP 5000) оптимизирован для использования всех преимуществ архитектуры SAS, модулей памяти NVMe и памяти класса Storage Class Memory (SCM). Время отклика платформы составляет всего 70 микросекунд, а архитектура ввода-вывода с автоматической защитой и четырехкратным резервированием матрицы обеспечивают показатели доступности данных на уровне 99.999999%.
Есть решения, которые подойдут и для среднего бизнеса, например, совсем недавно Hitachi Vantara расширила модельный ряд Hitachi Virtual Storage Platform серии E новыми моделями среднего уровня VSP E590 и E790. Они представляют собой платформы форм-фактора 2U, обеспечивают лучшую в своем классе производительность и защиту данных. В них используется та же операционная система SVOS RF, что и в серии VSP 5000, что позволяет сократить объемы и повысить эффективность.
Опыт HCI в России и в мире
Сегодня гиперконвергентная платформа Cisco HyperFlex активно применяется тысячами заказчиков по всему миру и более чем сотней компаний в России. Система задействована для решения широкого спектра задач: от построения инфраструктуры небольшого офиса до поддержки критичных систем управления предприятиями. Спектр возможных сценариев и сфер применения весьма разнообразен. Для того, чтобы ознакомится с лучшими практиками и вариантами использования, можно обратиться к опыту специалистов, который доступен в рамках программы Cisco Validated Design (CVD). Обширная библиотека документов шаги в рамках работ по проектированию и внедрению систем для различных сценариев использования HyperFlex. Например, для построения филиальной сети, внедрения нагруженных СУБД, интеграции с объектными и файловыми хранилищами и т.д.
«Сегодня востребованность и рост популярности гиперконвергентных систем у заказчиков в России вполне сопоставимы с тенденциями, наблюдаемыми на мировом рынке. Если говорить конкретно о HyperFlex, то в глобальном масштабе существует множество примеров перевода на эту платформу крупных критичных систем, при том, что в России заметна более существенная доля относительно небольших внедрений. Судя по всему, российские заказчики относительно более прогрессивны с точки зрения перевода на гиперконвергентные рельсы самых разных приложений, но, возможно, чуть более консервативны в части крупных и критичных нагрузок», — заключил Евгений Лагунцов.
Новое поколение коммутаторов Cisco Nexus 9000
Завершило пресс-конференцию выступление системного инженера Cisco Александра Скороходова, который представил новое поколение коммутаторов Cisco Nexus 9000. В этих сетевых устройствах впервые применены специализированные интегральные схемы (ASIC) с технологией 16 нм. Производительность оборудования составляет до 36 портов 100G на один чип. В новых коммутаторах скорости 25G и 100G будут стоить заказчику примерно столько же, во сколько обходятся 10G и 40G, соответственно, обеспечивая защиту инвестиций на ближайшее десятилетие. При этом многоскоростные порты (от 100M до 100G) дают заказчикам возможность наращивать скорость по мере готовности. Далее, телеметрия и информационная безопасность реализуются на скорости канала, а расширенная таблица маршрутизации в архитектуре leaf and spine обеспечивает шестикратное масштабирование IPv4, 12-кратное масштабирование IPv6 и масштабирование MAC-адресов в 1,8 раза, по сравнению с аналогичными коммутаторами, собранными на коммерческих чипсетах.
Представляя участникам конференции набор SDN-решений Cisco для ЦОД, Александр Скороходов основное внимание уделил новому поколению ACI – Application Centric Infrastructure, отметив, в частности, такие характеристики, как автоматизация на основе политик, открытость, опора на стандарты и встроенная безопасность, а также поддержка интеграции ACI с Nexus 7K/ASR 9K. Новое ПО Nexus Fabric Manager реализует ориентированную на сеть операционную модель и автоматизацию фабрики как для оверлейного, так и для базового слоев, с помощью нескольких щелчков мыши
Операционная система Cisco NX-OS для ЦОД теперь поддерживает такие опции, как сегментная маршрутизация, модернизация ПО без прерывания обслуживания и обнаружение микровыбросов, что обеспечивает заказчикам новый уровень контроля трафика, операционную гибкость, подробный обзор и информационную безопасность. Давая общую оценку решений SDN от Cisco, Александр Скороходов особо подчеркнул открытость в выборе подходов к сетевой автоматизации
Новое ПО Nexus Fabric Manager реализует ориентированную на сеть операционную модель и автоматизацию фабрики как для оверлейного, так и для базового слоев, с помощью нескольких щелчков мыши. Операционная система Cisco NX-OS для ЦОД теперь поддерживает такие опции, как сегментная маршрутизация, модернизация ПО без прерывания обслуживания и обнаружение микровыбросов, что обеспечивает заказчикам новый уровень контроля трафика, операционную гибкость, подробный обзор и информационную безопасность. Давая общую оценку решений SDN от Cisco, Александр Скороходов особо подчеркнул открытость в выборе подходов к сетевой автоматизации.
Понятно, что коммутаторы Cisco Nexus 9000 относятся к верхней категории сетевых устройств облачного масштаба, так что пока в России можно говорить лишь о десятке-другом примеров их внедрения. Если же брать мировые показатели, то тандем ACI/Nexus 9K насчитывает на сегодня более 6000 заказчиков.
Дмитрий Шульгин
- СХД
- ИТ-инфраструктура
- ЦОД
Есть ли среди СХД те, у которых риск потери данных выше?
Чем ниже класс решения, тем выше риски потери данных, и наоборот. Зачастую компании, которые только начинают расти, используют решения Entry Level. Поначалу все идёт хорошо, но потом возникают вопросы: а что, если сломается контроллер? Как его менять? Что делать, если нужен рост производительности? В связи с этим решение меняется на уровень Enterprise, с более низкими рисками потери данных. «В наших решениях используются диски, в которых может быть до 12 контроллеров, и даже если четверть из них выйдет из строя, данные останутся неповрежденными», – отмечает Алексей Никифоров.






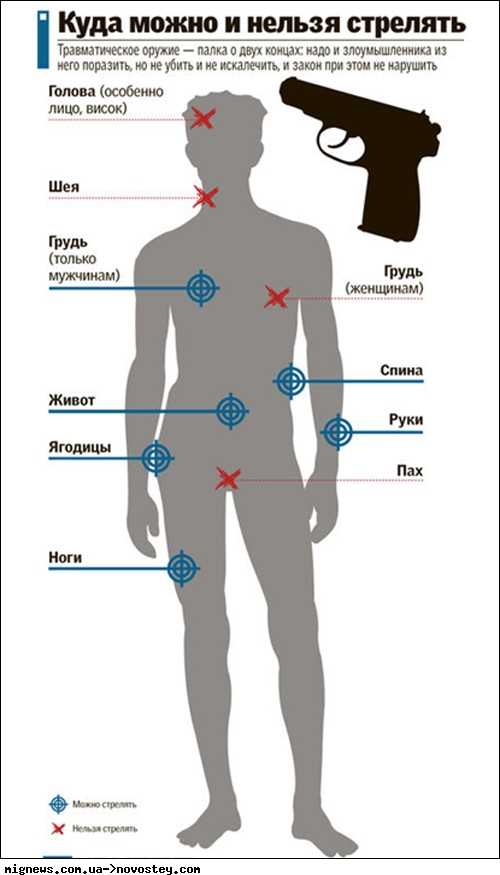
Однако при всех достижениях в технологиях защиты данных, нужно учитывать, что далеко не для каждой компании риски их потери могут быть критичными. Если в организации хранятся данные, которые «не жалко», то и беспокоиться по поводу надежности системы лишний раз не стоит.
Программа курса
Тема 1. Все, что нужно знать о рынке Hyperconvergence
- Типы конвергентной инфраструктуры
- Что такое гиперконвергенция
- Где используется гиперконвергенция сегодня?
- Новые IT-модели
- Насколько горяч рынок (статистика)
- Существующие игроки на этом рынке
— Nutanix, SimpliVity, EMC VxRail, HPE - Гиперконвергентная инфраструктура от первого поколения до нового поколения (HCI)
— Масштабирование и производительность
— Сети
— Интеграция и управление - Преимущества платформы данных нового поколения
— Программно-определяемые вычисления, хранилище и сеть - ASAP Data Center
- Видео: Введение в HyperFlex
- Упражнение: Как использовать тренды HCI при работе с клиентами
Тема 2. Обзор Cisco HyperFlex
- Анатомия HyperFlex
- Компоненты HyperFlex
— HyperFlex HX Data Platform
— Что внутри платформы данных HX
— Файловая система HX
— Модели HyperFlex HX-серии
[ — HCI с Converged Fabric Networking - Параметры работы и настройки кластеров
Тема 3. Отличительные особенности HyperFlex
- Чем HyperFlex отличается от других решений
- Интеграция в существующую инфраструктуру
- Упрощенная работа с HCI и CI, работающих вместе
- Динамическое распределение данных
- Упрощенное масштабирование
— Независимое масштабирование инфраструктуры
— Scaling-out - Интегрированные услуги управления
- HyperFlex Connect
- Автоматическое развертывание
- Архитектура UCS Fabric с использованием HyperFlex
Тема 4. HyperFlex Edge для филиалов и офисов малого и среднего бизнеса
- Изменение бизнес-ландшафта и новые требования к приложениям
- IT-операции на границе сети
- Решение HyperFlex Edge
- От ядра до края сети – позиционирование
Тема 5. HyperFlex как часть центра обработки данных
- Единая архитектура для простоты эксплуатации
- Cisco UCS Director с HyperFlex
- Cisco CloudCenter с HyperFlex
— Облачный опыт
— Оптимизация мощности
— HyperFlex с использованием CloudcCenter - Cisco Application Centric Infrastructure (ACI) с HyperFlex
- HyperFlex с Cisco Enterprise Cloud Suite (ECS) и ACI
- Защита данных в HyperFlex с использованием Veeam
Тема 6. HyperFlex Value Proposition
- Значение технологии HyperFlex
- Экономическая ценность
- Что все это значит для партнера
- Поддержка партнеров, включая обзор поощрений и акций
- Упражнение: Оценка возможностей рынка для HyperFlex
Тема 7. Как позиционировать HyperFlex. Работа с клиентами
- Проблемы клиентов
- Ориентир на бизнес-результат
- 5 ключевых преимуществ HyperFlex, на которых нужно сосредоточиться
- Где HyperFlex подходит, а где нет
- Основные варианты использования HyperFlex
- Позиционирование HyperFlex
- С кем поговорить
- Продажа существующим клиентам
- Почему HyperFlex актуален для бизнеса
- Истории успеха и тематические исследования
- Упражнение: Планирование продаж, выявление клиентов
Тема 7. Конкуренция и обработка возражений
Тема 8. Итоги и дополнительные ресурсы
- Призыв партнера к действию
- HyperFlex Sales Kit & Launch Hub
- Ресурсы для партнеров HyperFlex
5. Как выбрать класс оборудования?
Оборудование зависит от требований к надежности и доступности, а также от функциональных свойств решения. Как пояснил Алексей Никифоров, нишевое «железо», которое вполне справляется с нагрузкой небольшого магазина, не способно выполнить задачи большой компании, имеющей два ЦОДа с высокой производительностью, нагрузкой и репликацией. Высокопроизводительная СХД просто не будет работать на недорогом сервере. Решения enterprise-класса отличаются от бюджетных и нишевых решений тем, что в них заложены все необходимые технологии, обеспечивающие высокую отказоустойчивость и доступность. Правильный сайзинг СХД позволит не только определить класс и количество устройств для хранения данных, но и решить, будет ли это одна мощная станция или несколько серверов.
7. Какие компетенции потребуются от сотрудников для работы с СХД и смогут ли справиться с системой работники в удаленных регионах?
За последние годы произошла значительная консьюмеризация ИТ-систем, поэтому пользователям уже необязательно быть суперспециалистами. Даже администратору достаточно уметь выделять дисковое пространство в СХД и использовать по назначению. Работа с системой значительно упрощается, если она обслуживается вендором и имеет весь необходимый функционал. Высокопроизводительное оборудование enterprise-класса обладает набором инструментов, позволяющих решать сложные задачи и диагностировать состояние системы
При работе с недорогим железом важность компетенции пользователей возрастает, так как в нем нет инструментов, позволяющих понять, что сломалось и что делать, чтобы система заработала. География расположения установок значения не имеет.
Специальное умное «железо»
Михаил Орленко полагает, что развитие аппаратного обеспечения для высокопроизводительных вычислений идет по пути гибридизации, сочетания процессоров общего назначения и специализированных ускорителей. Еще недавно в основе процессорных вычислительных ресурсов лежали архитектуры RISC или x86, в последнее десятилетие для решения задач AI/ML мы перешли на GPU и FPGA, а в последние несколько лет все большую популярность набирают тензорные (TPU) и нейронные процессоры (NPU), рассуждает он.

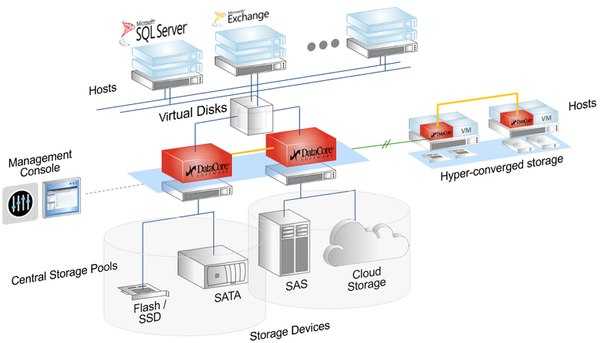





![Fc подключение к схд сервера под windows [colobridge wiki]](https://sariola.ru/wp-content/uploads/7/6/4/764199a972c448839215f09de2419784.jpeg)
| Но уже набирает силу следующая волна революции — ИИ-чипы станут перемещаться от ядра сети, ЦОД, к ее границе – периферии. По сравнению с традиционными архитектурами ЦП микросхемы ИИ помогут на несколько порядков быстрее выполнять параллельные вычисления и быстрее обрабатывать задания, связанные с искусственным интеллектом,- прогнозирует Михаил Орленко. |
В отличие от сегодняшних GPU и FPGA, эти микросхемы будут ориентированы на работу специализированных приложений, например, компьютерного зрения, распознавания речи, робототехники, беспилотного транспорта и, соответственно, будут оптимизированы для инференса, обработки естественного языка, выполнения заданий ML и DL.
Революция уже идет: в «Делойт» ожидают, что объем рынка ИИ-процессоров (для локальных устройств и ЦОД) вырастет с 6 млрд. долл. в 2018 году до более, чем 90 млрд. долл. в 2025 году, а среднегодовой темп роста составит 45%.
Причем, объем сегмента ИИ-процессоров для потребительских устройств (смартфоны премиальных линеек, планшеты, умные колонки и т.д.) сегодня намного больше сегмента для корпоративных устройств, но расти он будет медленнее: в период с 2020 по 2024 год ожидается увеличение в среднем на 18% в год. А вот рынок ИИ-процессоров для корпоративных устройств (роботы, видеокамеры, датчики и т.п.) значительно моложе (первый такой процессор поступил в продажу в 2017 году), однако растет он гораздо быстрее: в период 2020-2024 гг. ожидается среднегодовой рост на уровне 50%.
![]()
Таким образом, «мягкий» ЦОД, полностью программно-определяемый по всему множеству своих признаков, будет базироваться на все более сложном, производительном и умном «железе».